2 approvers is easy. 12 approvers, 40 apps, 3 identity groups per app, and no clear escalation path is where access approvals start to break.
If you need to create escalation paths for access requests, the mistake is usually starting with the org chart. That feels right, because escalation sounds like a people problem. But most access delays aren't people problems. They're workflow problems that got pushed into Slack because Jira didn't know what to do next.
I've seen this play out a bunch. A manager misses an approval, an app owner is on vacation, and Security needs to review an admin role. Nobody knows if IT should wait, nudge, approve, deny, or reroute. Then 2 weeks before the audit, someone is rebuilding the whole story from tickets, DMs, screenshots, and memory. Not fun.
Key Takeaways:
- Escalation paths for access approvals should be built around risk, not job titles.
- The first escalation decision is whether the request is blocked, stale, risky, or missing context.
- Jira should own the workflow record, while Slack can handle the fast approval moments.
- Time-bound access reduces the pressure to over-escalate low-risk temporary requests.
- Access reviews need escalation rules too, because stale certifications create audit gaps.
- Good escalation paths create audit evidence as the work happens, not after the fact.
Why Access Escalations Break When They Leave Jira
Access escalation breaks when the request, approval, provisioning, and audit evidence live in different places. Jira has the ticket, Slack has the nudge, the identity provider has the actual group change, and the spreadsheet has the audit story. That split creates delays, missed revocations, and a lot of manual cleanup later.

The Real Problem Isn't Slow Approvers
Approvers aren't the bottleneck most of the time. Some ignore requests, sure. Most don't. The bigger issue is that the workflow doesn't know what should happen when the normal approver doesn't respond, or when the request suddenly becomes riskier than expected. So everything becomes a judgment call.
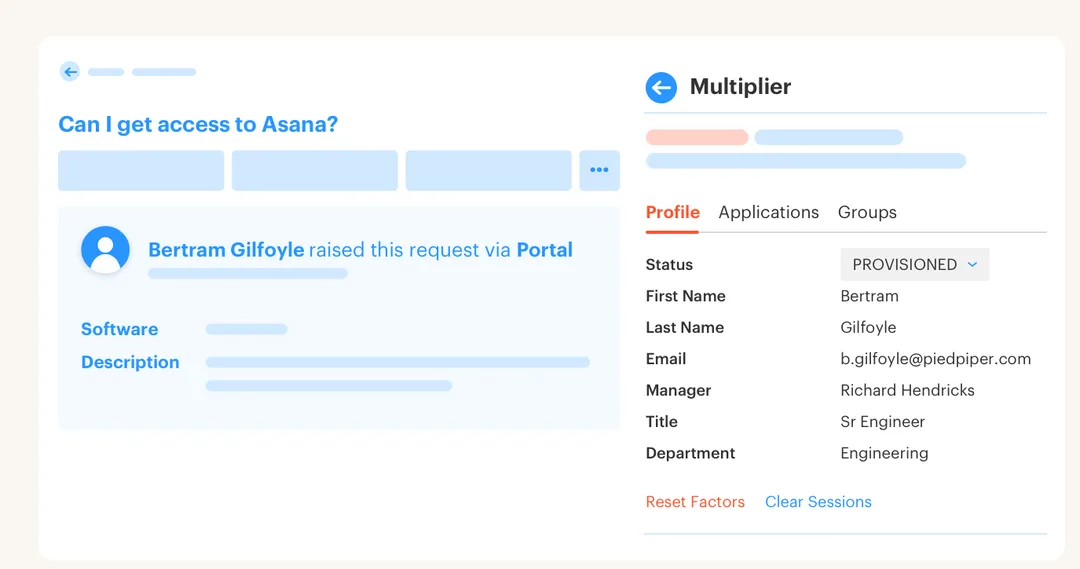
Picture a workplace technology manager at 4:48 PM on a Thursday. A sales leader needs admin access to a revenue tool for a board report due Friday morning. The manager is in back-to-back meetings, the app owner is in Portugal on PTO, and the request sits in Jira while the employee pings the #it-help Slack channel three times in an hour. Then someone says, "Can we just grant it and clean it up later?" That's the moment the process starts leaking.
Now multiply that by 50 apps. Or 200 employees. Or a quarterly access review where 9 reviewers need to certify permissions across systems they barely remember owning. Without escalation rules, your team creates one-off exceptions. And one-off exceptions are where standing privilege comes from. If you're trying to create escalation paths for access governance, start by assuming the normal path will fail sometimes.
A decent escalation path answers 4 questions before anyone gets stuck:
- Who owns the first decision?
- How long can the request wait?
- What changes when the request is privileged?
- What evidence gets written back to the ticket?
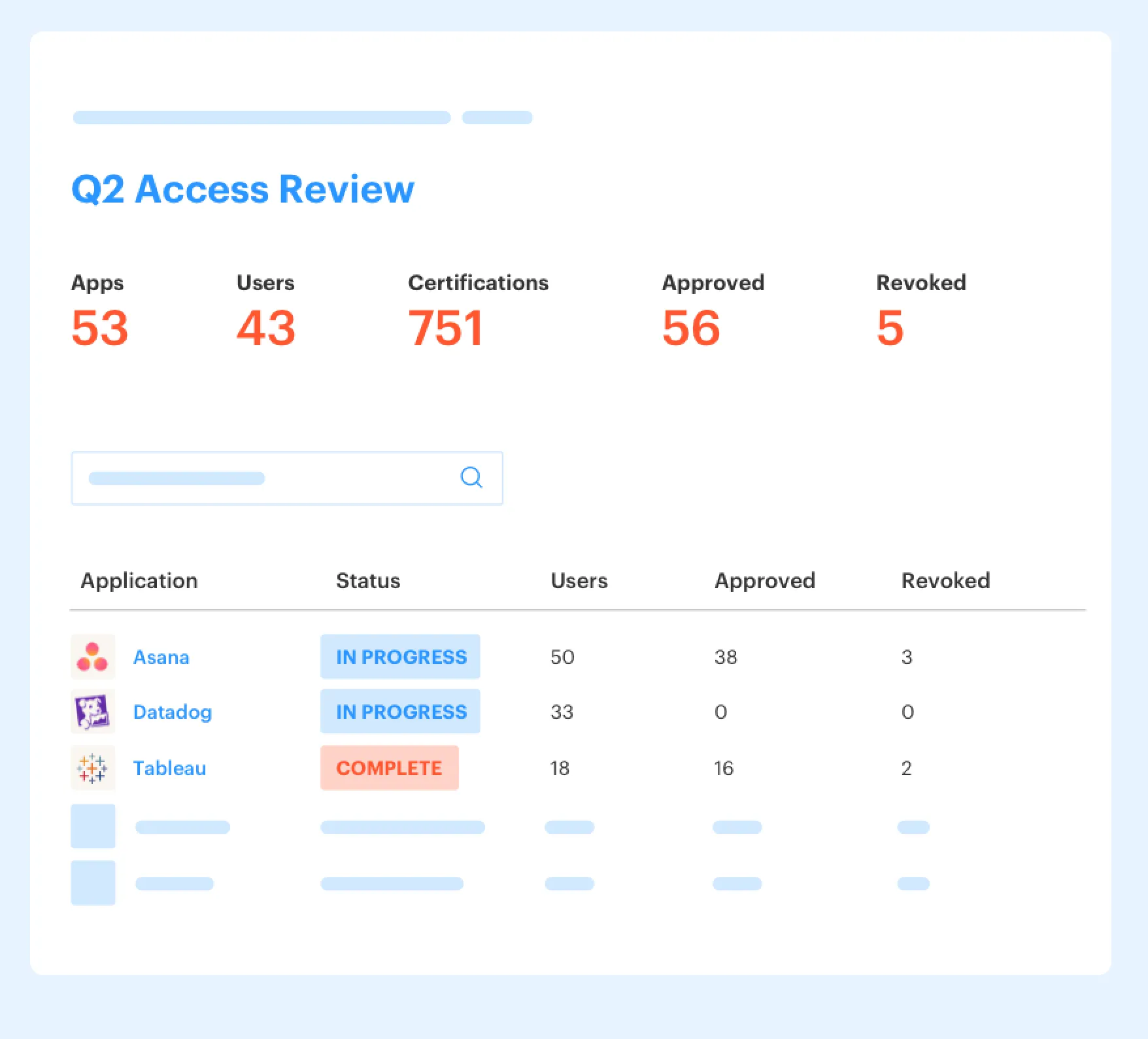
Spreadsheets Make Escalation Look Safer Than It Is
Spreadsheets feel safe because everyone can see the rows. I get why teams use them. If you're small, a sheet with app owners, backup approvers, and review status can work for a while. It's flexible, cheap, nobody has to configure anything, and that's a reasonable read.
The catch: a spreadsheet doesn't execute anything. It doesn't move the Jira issue. It doesn't remove a user from an identity provider group. It doesn't prove that the backup approver reviewed the request at the time. It just stores a version of what someone hoped happened. And in access governance, hoping is expensive.
At Luno, the access request problem grew because requests came from Slack, email, and Jira, while IT still had to chase managers and manually perform group assignments in Okta. At Synthesia, access lived in Slack and Notion while the company added 200 new employees a year. Those aren't weird edge cases. That's what happens when growth outruns the workflow.
The first fix is not more reminders. It's to create escalation paths for the system of record, then let chat support the workflow instead of becoming the workflow.
The Audit Problem Starts Months Before The Audit
Audits become painful when evidence is created after the work instead of during the work. The access was requested in one place, approved in another, provisioned somewhere else, and reviewed in a spreadsheet. Then the team has to stitch the story together after the fact. I've been in those rooms. Everyone gets weirdly calm, which usually means the panic is just being spread across 5 people.
Escalation makes this worse because escalation usually happens under pressure. Someone needs access now. Someone is blocked. Someone important is asking why IT is slowing down the business. When there isn't a defined escalation path, the team optimizes for speed and cleans up evidence later. Sometimes later never comes.
That doesn't mean every request needs a heavy process. Actually, the opposite. Low-risk access should move fast. Temporary elevated access should expire. High-risk access should get routed to the right approver and, if blocked, escalate based on time and risk. If the rule is clear, IT doesn't have to play judge every time.
If you already run Jira Service Management for access intake, See how Multiplier handles this in the context of keeping those approvals, escalations, and evidence tied to the same Jira record.
How To Create Escalation Paths For Access Requests
To create escalation paths for access requests, define the request types, risk levels, wait times, fallback approvers, and evidence rules before volume spikes. The goal isn't to chase people faster. The goal is to make the next action obvious when the normal approval path fails.
Start With Request Buckets, Not Approver Names
Names are brittle. People move, leave, go on PTO, change teams, or don't understand why they're being asked to approve something. Starting an escalation design with "Sarah approves marketing tools, Raj approves engineering tools" feels concrete on day one and falls apart by quarter two.
Start with request buckets instead. Not fancy, just practical. Standard app access, elevated access, time-bound access, exception access, and access review revocations. Each bucket gets its own escalation logic because each one has a different risk profile. Standard access can wait a few hours. Production admin access probably can't sit for 3 days. A revoke decision from an access review shouldn't depend on a reviewer remembering to follow up manually.
Here's a diagnostic that takes 20 minutes: pull your last 25 access tickets and ask what actually blocked them. Not what the ticket status says. What really happened. If 10 were waiting on manager approval, 6 were missing app owner context, 5 required identity provider group mapping, and 4 were security-sensitive, your escalation paths should match those patterns. Whatever your top two blockers are, that's where the first two escalation rules go.
Use a simple sorting rule:
- Standard access: escalate after 1 business day to backup app owner or manager.
- Privileged access: escalate after 2 to 4 hours to security or the system owner.
- Time-bound access: escalate fast, but require expiry before provisioning.
- Missing context: return to requester, don't escalate.
- Review revocation: escalate to campaign owner if reviewer doesn't act by the review window.
The hidden advantage is focus. Once requests are bucketed, escalation paths stop being personal. Nobody is asking, "Why did you skip me?" The workflow is just following the rule.
Put Time Limits On The Escalation Path
Access work needs clocks. Without clocks, everything becomes "waiting." Waiting for manager. Waiting for app owner. Waiting for IT. Waiting for security. Waiting is where tickets go to die.
The clock should depend on the access type. For low-risk apps, 24 business hours is usually fine. For admin roles, database access, production systems, finance tools, or customer data tools, the escalation window should be much shorter. If the access is temporary and tied to a real business need, 2 to 4 hours can be reasonable. If it's permanent privileged access, slow down. Different problem.
A simple escalation path can look like this:
- Request created in Jira with app, role, business reason, and duration.
- Primary approver gets notified.
- If no action after the threshold, Jira routes to backup approver.
- If still blocked, security or IT owner reviews based on risk.
- If approved, provisioning happens through the identity provider group.
- If time-bound, revocation is scheduled at expiry.
- Ticket records every decision and change.
That last part matters. Escalation without evidence is just a faster mess. The ticket should show who approved, who was skipped, why the backup approver acted, what group changed, and when the access ends. Otherwise the escalation path solved the employee problem but created an audit problem.
A lot of teams resist time limits because they're worried about annoying approvers. Valid concern. Nobody wants Slack DMs every 15 minutes for low-risk requests. The nuance is that escalation windows should be tied to risk, not urgency theater. An executive asking loudly doesn't make the request low-risk. A production incident doesn't make permanent access acceptable.
Build Backup Approvers Around Ownership, Not Hierarchy
Why do most escalation paths default to the org chart? Because the org chart is sitting right there in Workday. It's easy. Manager to director to VP. The VP has authority, sure. But they may have no idea whether the person should get GitLab admin access or finance system export permissions.
Better backup approvers are app owners, system owners, team leads, or security reviewers depending on the request. For a standard marketing tool, the app owner or department lead is probably enough. For privileged engineering access, a security reviewer or platform owner should be involved. For license-heavy SaaS, IT may need usage context before approving another seat.
Stavvy is a good example of why this matters. They had long-lived privileged access after funding and acquisitions, and they needed time-bound access that fit their Atlassian workflows. The real win wasn't just "approve faster." The win was segmenting access by risk, setting time limits, and reducing privileged access by 85%. That only works when the escalation path respects the risk.
One mistake I see a lot: teams create backup approvers but don't define what they're allowed to approve. That's dangerous. A backup approver for standard access shouldn't automatically become a backup approver for admin access. Same person, different risk. The workflow needs to know the difference.
If you're unsure how to assign backup approvers, use this decision rule:
- If the request changes data exposure, route to security.
- If it changes system configuration, route to app owner or platform owner.
- If it only adds a standard user role, route to manager or app owner.
- If it creates cost, include IT or the budget owner.
- If it lacks a business reason, send it back to the requester.
Make Missing Context A Stop, Not An Escalation
Missing context should not escalate. It should bounce. I know that sounds harsh, but it's one of the cleanest ways to reduce access risk. If the request doesn't include the app, role, reason, duration, or requester details, there's nothing meaningful to approve.
A lot of teams treat missing context like an IT task. The ticket comes in vague, then IT starts detective work. What role do you need? Who approved this? How long do you need it? Is this for a customer issue? Is this production or sandbox? That back-and-forth feels helpful, but it turns IT into the intake quality team for every department.
A better escalation path separates "blocked by person" from "blocked by information." Those are completely different problems. If the manager hasn't approved, escalate to a backup approver. If the requester didn't say why they need admin access, return the ticket with required fields. Don't send bad context up the chain. You'll just get faster bad approvals.
The fastest teams I've seen do this with a catalog. Employees pick the sanctioned app, select the role, add a reason, and choose a duration if needed. That forces enough structure upfront that approvers can make a decision without 6 follow-up comments. Not perfect. But much better.
For access escalation paths, the rule is simple: people delays escalate, bad inputs return.
Tie Access Reviews To The Same Escalation Logic
Access reviews are where weak escalation paths really show up. During normal access requests, a delay is visible because an employee is blocked. During access reviews, the delay is easier to ignore. A reviewer doesn't respond, a campaign sits at 64% complete, and a revoked user isn't actually removed. Then the audit asks for proof and everyone starts digging.
Reviewer escalation needs its own path. If an app owner doesn't complete a review by the target date, the campaign owner needs a clear next move. Maybe the review escalates to the app owner's manager. Maybe security reviews inactive users. Maybe IT executes revocations after a defined window when the recommendation is clear and usage shows no recent login. The point is not to wing it.
A good review escalation flow should answer:
- Who reviews each app?
- Who takes over if the reviewer doesn't respond?
- What happens when the recommendation is revoke?
- Who confirms the identity provider change happened?
- What export or record proves the campaign is complete?
I'd argue this is where Jira-native governance has the biggest advantage. Access reviews already feel like a campaign, but the work is still a series of decisions and changes. Jira is good at that. If the review decision, revoke action, and evidence all live together, you don't need to rebuild the trail later.
For teams trying to create escalation paths for access reviews, start with inactive users. They're easier to reason about. If someone hasn't logged in for 90+ days and the reviewer doesn't respond, the escalation path can be more direct than a sensitive active user with unclear business ownership. Different risk. Different path.
The access review use case is also where automation changes the team's posture from chasing to enforcing, and See how Multiplier handles this if you want to connect review decisions to Jira-native revoke actions instead of running the whole thing from a sheet.
How Multiplier Keeps Escalations Inside Jira
Multiplier keeps escalation paths inside Jira by turning access requests, approvals, provisioning, reviews, and revocations into Jira-native workflows. Employees can request access through JSM or Slack, approvers can act in JSM or Slack, and identity provider group changes are written back to the originating ticket.
Jira-Native Requests With Identity Provider Execution
Multiplier's Application Catalog gives employees a sanctioned place to request apps and roles from Jira Service Management, with the catalog synced from Okta, Entra ID, or Google Workspace. That matters because clean escalation starts with clean intake. If the request already includes the app, role, and mapped identity provider group, the approver isn't guessing.

The Approval Workflows then route decisions to managers, app owners, or specific users, with notifications in JSM and Slack. Once the request hits the configured approved status, Multiplier provisions through identity provider group assignments and records success or failure back in Jira. For SSO apps, that means the entitlement flows through the identity provider instead of someone copy-pasting group changes by hand.
Multiplier doesn't directly provision into every SaaS app. Worth saying. It provisions through identity provider groups, which is exactly why the workflow stays auditable and reversible. The Jira ticket becomes the dispatch board: who asked, who approved, what group changed, and what happened next. Much better than a screenshot folder.
Access Reviews With Revocations And Evidence
Multiplier's Access Reviews run certification campaigns in JSM, with reviewers seeing user attributes, groups, last login, and recommendations. Reviewers mark Keep or Revoke, and revocations remove users from the relevant identity provider groups while creating Jira evidence for the change. That's the part most teams miss when they create escalation paths for reviews.
Instead of a spreadsheet saying "revoke" and someone else doing the cleanup later, the decision and enforcement sit in the same workflow. Admins can export results as CSV or push evidence to systems like Vanta. The important point is that the evidence is produced from the work, not rebuilt after everyone forgets what happened.
Time-Based Access also fits the escalation model. Requesters can choose a duration like 1, 6, or 24 hours, and after approval, access is removed from the mapped group when the timer expires. Auto Reclaim can also identify inactive users from identity provider login data and revoke access after the policy threshold and grace period. Both reduce the number of escalations IT has to chase manually because the workflow already knows when access should end.
And for high-growth teams, that adds up. Synthesia processed 3,800+ access requests in a year with 75% fully automated, while a 4-person IT Ops team supported 420+ employees. That's not because they hired a bigger ticket-chasing team. They put the access workflow where the work already lived.
Build The Escalation Path Before The Exception Happens
Escalation paths are really just pre-decided judgment. You decide what happens when an approver is missing, when the request is risky, when context is incomplete, and when a reviewer doesn't act. Then Jira runs the play instead of IT making it up every time.
The old way is to grant access, clean it up later, and rebuild evidence when someone asks. That works for a while. Then growth hits, apps multiply, audits get sharper, and the cleanup becomes the job. The better move is to create escalation paths for access requests and reviews while the team still has room to think clearly.
Start with 25 tickets. Find the real blockers. Bucket the requests. Add clocks. Define backup approvers by risk. Return bad inputs. Tie review decisions to actual revocations. That's enough to get out of the mess. Not perfect. Repeatable.
Frequently Asked Questions
How do I create a backup approver for access requests?
To create a backup approver for access requests, start by identifying the roles associated with the request. You can designate backup approvers based on the type of access requested. For example, if it's a standard access request, the backup approver could be the app owner or the user's manager. In Multiplier, you can set up approval workflows that route decisions to the right people without leaving Jira, ensuring that if the primary approver is unavailable, the request can still be processed quickly.
What if an approver is on vacation during a critical request?
If an approver is on vacation, it's essential to have a backup approver in place. You can define these backup approvers based on the access type. For instance, if the request is for privileged access, route it to a security reviewer or another designated app owner. Using Multiplier's approval workflows, you can ensure that requests are automatically routed to the appropriate backup approver, minimizing delays and ensuring timely access.
Can I set time limits on access requests?
Yes, you can set time limits on access requests by implementing time-based access policies. When employees submit a request through Multiplier, they can choose a duration for their access (like 1, 6, or 24 hours). After approval, Multiplier automatically provisions the access and sets a timer to revoke it once the time expires. This ensures that access is only granted for as long as necessary, reducing the risk of standing privileges.
When should I escalate an access request?
You should escalate an access request when it becomes blocked or stale. For example, if a request is waiting for approval beyond the set time limit, escalate it to a backup approver. In Multiplier, you can define escalation paths based on the type of access and the associated risk. Typically, standard access requests can escalate after one business day, while privileged access should escalate within a few hours to ensure timely processing.
Why does my team need to use Jira for access requests?
Using Jira for access requests centralizes the entire process, making it easier to track approvals, provisioning, and audit evidence. Multiplier integrates with Jira Service Management, allowing employees to submit requests directly through Jira or Slack. This keeps everything in one place, ensuring that all actions are logged and easily auditable, which is crucial for compliance and reducing manual errors.