
By the time a 400-person company adds 40 people in a quarter, access work stops being a ticket problem. You can use notifications and task routing all day, but if approvals, provisioning, and evidence live in different places, the queue still wins. The new hire still DMs someone in Slack asking for Figma access on day three.
I've seen this pattern a lot. IT buys another portal, adds another approval step, creates another spreadsheet, and then wonders why employees route around all of it. The issue isn't that people hate process. It's that the process doesn't match how work actually happens.
Access governance gets treated like a separate security project. In practice, it's an operations problem with security consequences. And when the work already starts in Jira, moves through Slack, and ends in Okta or Entra, forcing everyone into a separate IGA portal feels backwards.
Key Takeaways:
- Notifications and task routing only work when the actual access change is tied to the same record.
- Separate IGA portals create context switching, which slows approvals and weakens audit evidence.
- Jira should be the system of record for access work if your team already runs IT through JSM.
- Slack approvals are useful, but only when they create governed Jira actions behind the scenes.
- Access reviews need usage context, not just a spreadsheet of names and apps.
- The better model is request, approve, provision, review, and revoke from one workflow.
Why Notifications and Tasks Don't Fix Access Governance
Notifications and task routing fail when they only remind people to do manual work somewhere else. Jira can assign the ticket, Slack can ping the approver, and the identity provider can hold the actual permission, but the workflow still breaks if no single system owns the full chain. That gap is where access delays, standing privileges, and audit cleanup usually start.

The ticket looks organized, but the work isn't
Picture a Tuesday at 9:14 AM. A new product manager fills out a JSM form asking for Figma Editor and Mixpanel access. The form pings her manager in Slack, who approves from his phone while walking into a standup. An IT analyst sees the Slack notification 40 minutes later, opens Okta, manually adds her to two groups, then goes back to the Jira ticket and writes "done" in the comments. Total elapsed time: 3 hours. Total systems touched: 4. Audit evidence: a Slack message, a Jira comment, and whatever Okta's logs caught.
That's not governance. That's a relay race where every runner is holding a different map.
At Luno, rapid growth pushed hundreds of routine access requests into Slack, email, and Jira. The IT team had to chase managers, manually assign Okta groups, and keep logs for auditors. That's the part people underestimate. The ticket volume wasn't the only problem. The problem was that every request required little jumps between systems, and those jumps created risk.
Think of it like airport baggage handling. A tag on the suitcase is useful, but only if the bag actually moves through a connected system from check-in to plane to carousel. If someone has to carry it across terminals by hand, you don't have a system. You have a person trying not to drop things.
Task notifications don't equal accountability
Notifications are useful. I'm not anti-notification. The problem is that a notification is not the same as ownership, and a task is not the same as a completed access change. If your workflow ends with "please go do this in Okta," you've just moved the burden from Jira to a human.
The diagnostic is pretty simple. Pick 20 completed access tickets from last month and check three things: can you see who approved it, can you prove what changed in the identity provider, and can you show whether access was later removed? If more than 3 of those 20 require screenshots, Slack searches, or spreadsheet lookups, your notification process is hiding manual governance.
That might sound harsh, but it's a fair test. Some teams keep manual steps on purpose because they don't trust automation for higher-risk apps. That's a reasonable read. Not every request should be auto-approved or provisioned without review, and for production database access or finance tools, a human pause is the right call. The issue is different. Even manual decisions should leave evidence in the same place where the request started, because otherwise the audit story gets rebuilt later by whoever has the most patience.
If your JSM queue already has the right tickets but the wrong follow-through, Learn more about Multiplier in the context of the workflow you already run.
The audit problem starts months before the audit
Audits get painful because the evidence wasn't created when the work happened. The request came in, the approval happened somewhere, and the access change happened somewhere else. Then, 90 days later, someone asks for proof and everyone starts reconstructing the story from comments, exports, and memory. Very fun. Everyone's favorite week.
A better question is: if an auditor picked one employee and one app, could you trace the full chain in under 2 minutes? Request, approval, grant, expiry if applicable, review decision, revoke if needed. If the answer is no, you don't really have audit readiness. You have audit recovery.
That's why using notifications and task routing as the main fix misses the point. The root cause isn't missed pings. It's disconnected evidence.
How to Make Notifications and Task Routing Actually Work
Notifications and task routing work when they move governed work forward, not when they remind someone to leave the workflow. The better model is to keep request intake, approval, provisioning, review, and revocation attached to the same operational record. For Jira-first teams, that means designing access governance around JSM instead of adding a separate portal beside it.
Start by separating requests from changes
Most access workflows confuse a request with a change. A request is the employee asking for Salesforce Editor access. A change is the identity provider group assignment that actually grants it. If those two things aren't linked, the team can approve the right thing and still lose track of what happened.
I like starting here because it cuts through the tool debate pretty fast. Take your top 10 requested apps and map each one to the identity provider group that grants the role. Viewer, Editor, Admin, whatever you use. If you can't map the role to a group, the request will always need human interpretation, and human interpretation is where access work slows down.
Run the mapping like this:
- List the 10 apps with the most access requests.
- Write down the available roles employees can request.
- Match each role to the identity provider group that grants it.
- Mark apps where provisioning is manual or non-SSO.
- Decide which roles need approval, time limits, or both.
The goal isn't perfection on day one. Honestly, trying to clean up every app before you launch is where these projects go to die. Start with the boring apps that create the most tickets, because those give you the fastest proof that the model works.
Use Slack for decisions, not as the system of record
Slack is great for approvals because people actually look at it. That's the whole point. If you force a VP to log into a separate governance portal to approve a low-risk app request, they'll ignore it until someone pings them anyway. Slack wins because it matches behavior.
The trap is treating Slack as the record. A DM approval might feel fast, but if the decision doesn't update the Jira issue, trigger the next status, and connect to the eventual access change, you've created another evidence problem. The approval happened, but now someone has to prove it later.
A useful rule: Slack can be the front door for the decision, but Jira should hold the record. If an approver clicks approve in Slack, the JSM issue should move. If the issue moves, the right task should fire. If provisioning happens, the ticket should show success or failure. Anything less is just chat with better formatting.
Build expiry into the request, not the cleanup
Time-bound access works best when duration is selected during the request. Asking IT to remember cleanup later is a bad bet. Not because IT is careless. Because they're busy, and the next request is already in the queue before the last one is fully cleaned up.
For elevated roles, I'd make duration a required field. One hour, 6 hours, 24 hours, maybe 7 days for some operational needs. If someone needs longer, they can request longer. What matters is that the default assumption changes from "grant and remember later" to "grant for a defined window."
A simple access duration policy could look like this:
- Admin roles default to 1 to 24 hours.
- Production or finance access requires approval and expiry.
- Standard SaaS roles can be permanent if tied to job need.
- Contractor access expires by default.
- Extensions use the prior approval only when the original request was already approved.
There's a case for permanent access. I don't think every app needs just-in-time rules, and for core job tools like email or the team's CRM, permanent access is normal. The point is to stop treating sensitive access like a normal software license, because that's how standing privilege piles up.
Make access reviews about decisions, not data entry
Access reviews fail when reviewers are asked to certify a spreadsheet they don't trust. Name, app, role, maybe department. That's usually not enough context to make a good call, so reviewers rubber-stamp the list or send follow-up questions. Then the review gets delayed, and revocations become another queue.
The better approach is to bring usage context into the review itself. Last login matters. Department matters. Job title matters. Group membership matters. If someone hasn't logged into an app in 90 days, the reviewer should see that at the moment they're deciding whether to keep or revoke access.
The decision rule is pretty straightforward. If a reviewer can't make a keep or revoke decision in under 30 seconds for standard apps, the review lacks context. If every revoke decision creates a separate manual ticket, the review process is incomplete. Reviews should produce action, not just a record of someone saying action is needed.
A strong review workflow gives reviewers:
- User attributes like department, title, and manager
- App and group membership context
- Last login or usage signals where available
- A clear Keep or Revoke decision
- A reason field for revocations
- Evidence tied back to the campaign or ticket
That last part matters more than people think. A review without enforced revocation is basically a suggestion box.
Use notifications and task routing to remove handoffs
The best use of notifications and task routing is to remove handoffs, not create more of them. A requester shouldn't need to know who owns an app. An approver shouldn't need to hunt for context. IT shouldn't need to copy a group name from a ticket into an identity provider. The workflow should carry the context.
At Videoamp, growth from 100 to 500 employees created a Tuesday spike of access requests after new hires started. The queue filled up with incomplete requests, unclear ownership, and repetitive work. After moving to a self-service app catalog in JSM, they had 20 sanctioned apps available and processed 500+ app requests in 6 months, saving 70+ hours of IT productivity. The lesson wasn't "add more notifications." It was "make the request structured enough that the next task can happen without guesswork."
That's the overlooked piece. Task routing only gets better when the task is well-defined. If the request says "need access to analytics," someone has to interpret it. If the catalog asks for the app, role, duration, business reason, and routes to the owner, the workflow has a chance.
For teams trying to connect Slack decisions to Jira evidence and identity provider changes, See how Multiplier works after you've mapped the first 10 high-volume apps.
Measure the manual work you eliminated
Access governance projects often get measured too late. Teams wait until the audit or quarterly review to judge whether the process improved. I'd track it weekly at first, because the early signals are operational, not compliance-heavy.
Start with 4 numbers: request volume, approval time, provisioning time, and manual touches per ticket. Manual touches matter most. If an access request still needs 5 to 30 minutes of IT work after approval, notifications and task routing haven't fixed the expensive part yet.
Use a simple scoring method:
- 0 manual touches means the request is approved and provisioned through the workflow.
- 1 manual touch means someone reviews an exception.
- 2 to 3 manual touches means the workflow still has gaps.
- More than 3 manual touches means the ticket is mostly a reminder.
At Luno, the big win was reducing IT workload on access requests by 80%. That kind of improvement happens when routine requests stop requiring IT to chase approvers and manually assign groups. Not glamorous. Very valuable.
How Multiplier Anchors Governance in Jira
Multiplier anchors access governance in Jira by connecting the request, approval, provisioning action, access review, and evidence trail inside JSM. Employees can request sanctioned apps from a JSM catalog or Slack, approvers can act from Slack or Jira, and changes run through identity provider group mappings. The value is that the governance record stays attached to the work.
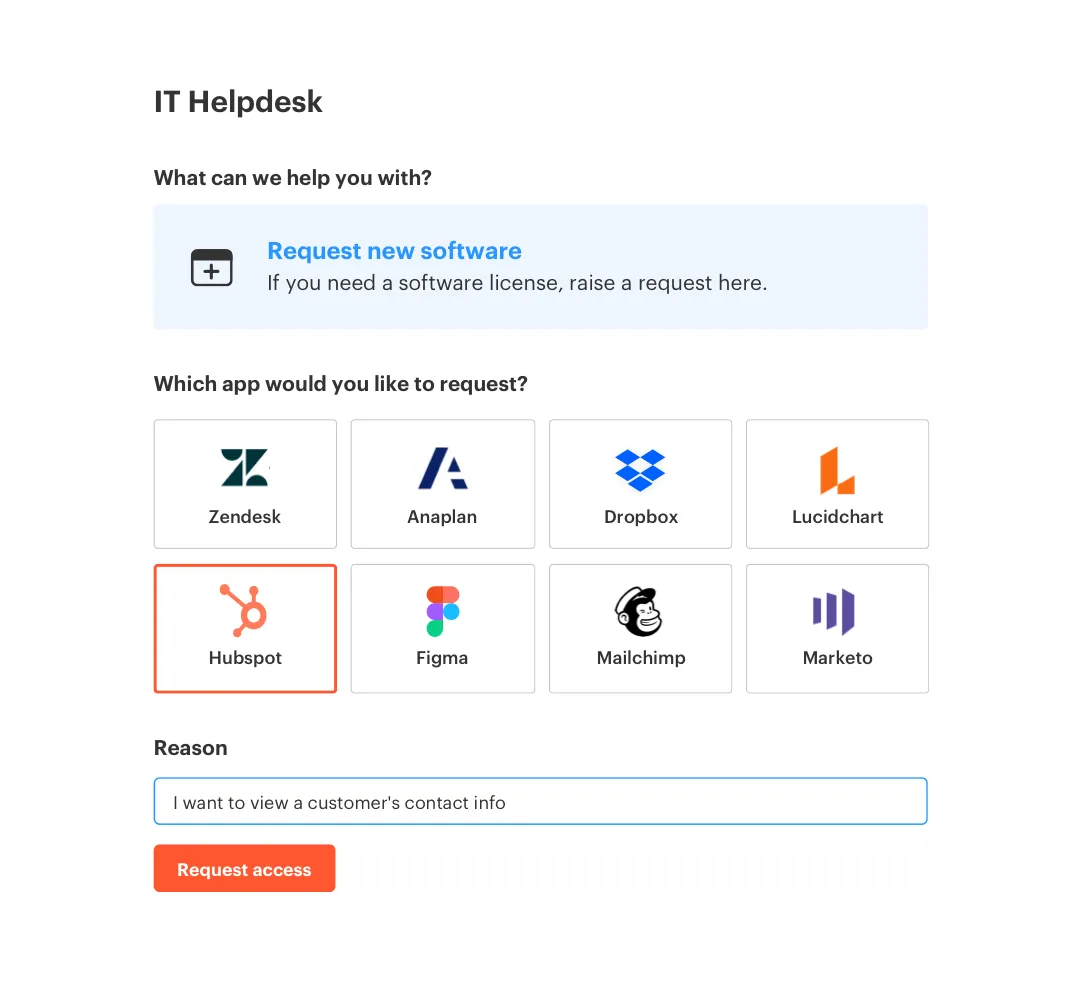
A Jira-native catalog gives structure to the request
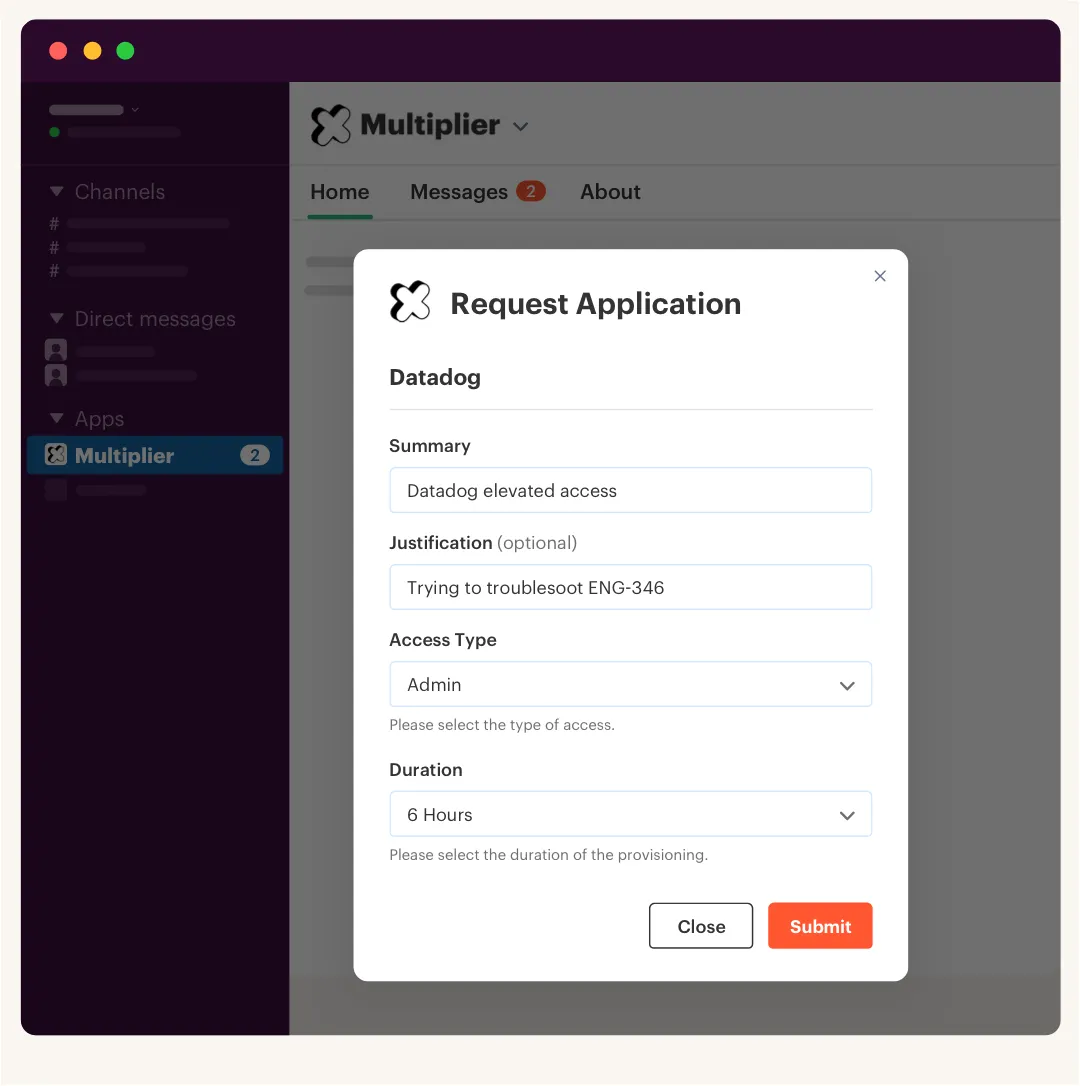
Multiplier's Application Catalog replaces ad hoc access requests with a JSM-native app store. Employees browse approved apps, pick a role like Viewer or Admin, and submit from the JSM portal or Slack. Behind the scenes, approved catalog roles map to identity provider groups in Okta, Entra ID, or Google Workspace, so the request is structured before anyone approves it.
That matters because structured intake makes notifications and task routing useful. The approver gets the right context. The Jira issue moves through the right status. After approval, Multiplier can provision through mapped identity provider groups and write the result back to the ticket. For non-SSO or manual apps, teams can still capture the request and retain the audit trail in Jira, which is often the first practical step.
Multiplier also supports Approval Workflows where decisions route to managers, app owners, or specific users through JSM and Slack. The Slack App doesn't replace Jira as the record. It creates or updates the JSM issue, and approvers can act from the place they already check. That's the right split: Slack for speed, Jira for evidence.
Reviews and revocations happen in the same workflow
Multiplier's Access Reviews run as Jira-native campaigns, not spreadsheet exercises. Reviewers see user attributes, group memberships, last login, and recommendations inside JSM, then choose Keep or Revoke. When they revoke access, Multiplier removes users from the relevant identity provider groups and creates Jira tickets documenting the change.

That closes the loop most teams leave open. The earlier problem was audit recovery, where someone had to rebuild the story from screenshots and exports. With Multiplier, the request, approval, grant, review decision, and revocation all connect back to Jira records. For teams dealing with standing privilege, Time-Based Access also lets requesters choose a duration like 1, 6, or 24 hours, then removes access from mapped groups when the window expires.
Auto Reclaim adds another layer for SaaS waste, using last-login data from the identity provider to identify inactive users, notify them, and revoke access after a grace period if they remain inactive. It's available on the Advanced edition, and it depends on accurate login telemetry from the identity provider. A real limitation worth naming. For apps with good telemetry, though, it turns license cleanup into a governed workflow instead of another spreadsheet hunt.
If your team already runs IT work in Jira and wants access requests, reviews, and revocations tied to the same record, Get started with Multiplier from the workflow you already trust.
Access Work Belongs Where Work Happens
Access governance doesn't get better because you added more reminders. It gets better when the request, approval, change, review, and evidence all live in one operating model. For Jira-first teams, that means you use notifications and task routing to move governed work forward inside JSM, not to send people into another portal.
The practical move is simple. Pick the high-volume apps first, map roles to identity provider groups, put approvals where people respond, and make Jira the record. Once that works, add time-bound access, reviews, and license cleanup. Focus creates momentum.
Separate portals can work for large teams with dedicated governance staff. No argument there. For lean IT and security teams already living in Jira and Slack, the better path is usually not more process. It's making the process match where the work already happens.
Frequently Asked Questions
How do I set up time-based access for new hires?
To set up time-based access for new hires using Multiplier, follow these steps: 1) When the new hire requests access, ensure they select a duration, like 1, 6, or 24 hours, during the submission process. 2) After the request is approved, Multiplier will automatically provision access and set a timer to remove the user from the mapped group once the duration expires. 3) If the new hire needs an extension, they can request it, and if the prior request was already approved, Multiplier can extend the access without needing re-approval. This process helps minimize standing privileges and ensures access is only granted when necessary.
What if I need to revoke access for a user?
To revoke access for a user in Multiplier, you can follow these steps: 1) Use the Access Reviews feature to identify users who should have their access revoked based on criteria like inactivity. 2) When you decide to revoke access, simply mark it as 'Revoke' during the review process. 3) Multiplier will automatically remove the user from the relevant identity provider groups and create a Jira ticket documenting the change. This ensures that revocations are tracked and evidence is maintained within the same system.
Can I customize the application catalog for my team?
Yes, you can customize the application catalog in Multiplier. To do this: 1) Admins can add custom applications to the catalog for non-SSO tools, ensuring that all access requests are captured. 2) You can also tag applications based on their provisioning needs, such as marking them for manual provisioning. 3) Make sure to set the status of each app to 'Approved' so that they are visible in the catalog for employees to request. This customization helps streamline the access request process and ensures consistency.
When should I use Slack for approvals?
You should use Slack for approvals when you want to speed up the decision-making process. Here's how: 1) Enable the Multiplier Slack App to allow approvers to receive notifications directly in Slack, where they can quickly approve or deny requests with a click. 2) Ensure that all approvals made in Slack are linked back to the Jira issue so that all evidence and documentation remain intact. 3) This approach minimizes context switching and keeps the workflow efficient, as approvers can act from the tool they use daily.
Why does my access request process seem slow?
Your access request process may seem slow due to disjointed systems and manual steps. To improve it: 1) Ensure that your access requests are linked to the same operational record in Jira, where approvals, provisioning, and reviews happen. 2) Use Multiplier to automate provisioning through identity provider groups, which eliminates the need for manual group assignments. 3) Streamline your request intake by using the Application Catalog to provide a clear and structured way for employees to request access, reducing confusion and delays.







