Access delays look like an efficiency problem. They’re usually a governance problem.
That distinction matters if you care about the impact of delays. Because once access is slow, teams start making bad tradeoffs. They grant broad standing access to avoid tickets. They approve in Slack without a clean record. They rebuild evidence in spreadsheets later and call that governance.
Key Takeaways:
- The impact of delays is bigger than lost time. It leads to standing privilege, extra SaaS spend, and weak audit evidence.
- Most access delays come from fragmented tools, not from approval policy itself.
- Faster access only works if provisioning, approvals, and audit evidence stay tied to the same workflow.
- Time-bound access cuts risk because access expires automatically instead of lingering for months.
- Access reviews work better when reviewers can act in Jira with real usage context.
- Identity governance works best when it lives in Jira and Slack, not in a separate portal.
Why the impact of delays gets worse as companies grow
The impact of delays gets worse as headcount, apps, and approval paths increase. What starts as a few annoying tickets turns into a system problem that slows work, weakens least privilege, and raises audit cost. Most teams don’t notice the shift until the queue is already broken.

Slow access is usually a system design problem
Most teams think access delays happen because approvers are slow. Sometimes that’s true. But usually that’s not the real issue.
The real problem is the work is split across too many places. The request starts in Jira. The approval happens in email or Slack. Provisioning happens in Okta or Entra. Evidence gets dumped into a spreadsheet because nobody trusts the ticket alone. So even a simple request has four handoffs before anyone gets access.
I’ve seen this pattern in content ops, sales ops, and identity work. Same movie. Once the process crosses too many tools, nobody owns the whole thing anymore. Each person does their tiny part. Meanwhile the requester waits.
And that wait has a cost. A new hire can’t do basic work. An engineer can’t get temporary elevated access during an incident. IT burns time chasing down who owns what. Sound familiar?
Fragmentation creates hidden delays nobody measures
This is where teams go wrong. They measure ticket resolution time, but not the delay between steps.
A request can sit for 6 hours waiting for the right approver to see a message. Then another 4 hours because the approver said yes in chat but no one updated the ticket. Then another day because someone has to manually add the user to a group in the identity provider. Then later, during an audit, someone spends 15 minutes trying to prove what happened. That all counts. That’s the impact of delays.
Luno ran into this as they grew. They were dealing with hundreds of routine access requests manually across Slack, email, and Jira while IT agents had to ask managers for approval and then log into Okta to perform the group assignment. That’s not a small inefficiency. That’s a queue that eats your team alive.
VideoAmp saw a version of the same problem during growth. New hires would start on Monday, and by Tuesday the IT queue was full of access requests. They had requests coming in without enough context to act on quickly. So the work piled up. It always does.
The emotional cost is real too
If you’ve ever run a lean IT or security team, you know this feeling. You’re not just behind. You’re being interrupted from every direction, and every request feels urgent even when it shouldn’t.
That’s what makes the impact of delays so frustrating. You know the work is repetitive. You know it shouldn’t be this hard. But the system keeps forcing humans into the middle of every decision and every follow-up.
The real bottleneck is the split between Jira and governance
The split between Jira and governance is what creates most access friction. ITSM handles intake well, and identity tools handle group changes well, but when those systems aren’t tied together, humans become the glue. That is slow, brittle, and hard to audit.
Separate governance portals add drag
A lot of teams assume identity governance has to live in its own portal. I don’t buy that. Identity governance belongs in Jira.
Why? Because the work already starts there. Or it starts in Slack and still ends up there if you’re doing it right. Employees know Jira. IT lives in Jira. Audit evidence tied to a Jira issue is far cleaner than trying to reconstruct what happened from chat threads and screenshots later.
VideoAmp tried using Okta’s self service request feature and ran into a familiar problem. It sent users to a separate portal, which was less friendly, less customizable, and weaker from an audit standpoint than doing the work in Jira. That’s the old way. Add another portal. Hope people use it. Then wonder why adoption is bad and the record is messy.
Some teams prefer dedicated IGA suites, and fair point, there are cases where deep policy matters. But if the operational reality is still Jira tickets, Slack pings, and manual group assignments, then the control model looks better on paper than it does in practice.
Manual enforcement breaks least privilege
Least privilege sounds great in policy docs. In real life, it fails when enforcement is manual.
If access takes too long, people stop asking for the narrow thing they need. They ask for the broad role that avoids future tickets. Admins approve longer durations because they don’t want to revisit it. Temporary access becomes permanent because nobody remembers to clean it up. So the impact of delays isn’t just slow work. It’s overprovisioning.
Stavvy is a good example of why this matters. They needed to minimize long-lived privileged access as they grew and handled sensitive financial data. Their issue wasn’t just approval speed. It was making sure elevated access existed only when needed and expired after that. Without that enforcement, you’re just trusting cleanup to happen later. It rarely does.
Audit pain is usually the result of delayed workflows
Audits get messy long before the auditor shows up. The mess starts when the workflow doesn’t produce evidence by default.
If approvals happen in one system, provisioning in another, and revocation somewhere else, you don’t have an audit trail. You have a scavenger hunt. Then somebody exports CSVs, grabs screenshots, pastes comments into tickets, and calls it good enough.
That’s why the impact of delays keeps compounding. A request delayed today becomes an evidence problem next quarter. A missed revocation today becomes an access review problem later. These aren’t separate issues. Same root cause.
What high-functioning teams do to reduce the impact of delays
High-functioning teams reduce the impact of delays by collapsing intake, approval, provisioning, and evidence into one operational flow. They don’t rely on policy alone. They design the workflow so the right action happens quickly and leaves a clean record.
Put the request where users already work
First, stop making people hunt for the right place to ask. That sounds basic, but it matters a lot.
When requests come through email, DMs, Slack threads, and random forms, the queue gets noisy fast. Some requests have no role detail. Some have no owner. Some skip approval entirely because someone said yes casually in chat. It’s a mess. A single request path fixes more than most teams expect.
The better model is simple:
- Put access requests in a single Jira-native flow.
- Show only approved apps and roles people should request.
- Capture the right context at submission, before the ticket is created.
- Route the ticket immediately to the right owner or manager.
That alone cuts a lot of delay. Not all of it. But a lot. And frankly, teams often underestimate how much waste sits in bad intake.
Make approval part of the workflow, not a side conversation
Approvals need to happen inside the actual process, not beside it.
When the approver can act in the same workflow the request belongs to, cycle time drops and the record stays clean. When approval is a side conversation, you get ambiguity. Someone says “approved” in Slack. Someone else misses it. The ticket stays open. Or gets closed without proof. All bad options.
The operating model I prefer is pretty direct:
- Define who approves each app or role ahead of time.
- Route the request to that person automatically.
- Let them approve in the tools they already use.
- Write that decision back to the system of record immediately.
Synthesia had a four-person IT team supporting a company that grew from 100 to over 400 employees in two years. Their earlier process ran through Slack channels and a Notion board. As they described it, notifications got missed and the process was very manual, very tiresome. That’s what approval outside the workflow does. It creates delay nobody wants to own.
After the methodology section, if you want to see what this looks like in practice, See How Multiplier Works.
Provision through the identity provider, not by hand
This is the part many teams skip. They fix intake. They maybe fix approvals. But they leave provisioning manual.
That’s a mistake. Because the manual group assignment is often where the queue really stalls. Somebody has to notice the approval, log into Okta or Entra, find the right group, make the change, maybe assign a license, then update the ticket. Every one of those steps adds delay and risk.
The stronger approach is to map roles to identity provider groups ahead of time, then let the approved workflow trigger the change automatically. That gives you consistency. It also gives you a clean audit path because the change is tied back to the ticket that initiated it.
There’s another benefit people miss. When provisioning flows through the identity provider, revocation gets easier too. That matters a lot for the impact of delays, because the same system that speeds up access can also remove it cleanly later.
Make temporary access the default for risky permissions
Most elevated access shouldn’t be permanent. It should expire unless there’s a real reason it shouldn’t.
This is one of those things people agree with in theory and avoid in operations because it sounds like more work. It’s actually less work when the duration is built into the request itself. A user asks for 1 hour, 6 hours, or 24 hours. Approval happens. Access is granted. Then it drops off automatically when time is up.
That model changes behavior. People ask for what they need now, not what they might need later. Security risk drops. License waste drops too. And the ticket becomes the evidence trail for the request, the approval, the grant, and the expiry.
Run reviews with context, not spreadsheets
Quarterly access reviews go sideways because reviewers don’t have enough context. So they click keep, keep, keep, and move on.
A better review process puts usage and user context in front of the reviewer at decision time. Last login. Department. Job title. Group membership. Maybe a recommendation to revoke if someone’s been inactive for 90 days. That changes the quality of the review.
And if the revoke action actually executes from the review workflow, even better. Now you’re not creating a second cleanup project after the campaign ends. You’re finishing the governance loop in one motion.
How Multiplier turns delay-heavy access work into a cleaner Jira flow
Multiplier turns delay-heavy access work into a cleaner Jira flow by keeping requests, approvals, provisioning, reviews, and evidence tied to Jira Service Management instead of spreading them across disconnected tools. That cuts the operational drag behind the impact of delays and makes least privilege easier to enforce day to day.
A single request path with approvals that don’t get lost
Multiplier’s Application Catalog gives employees a Jira-native place to request approved apps and roles through JSM, and the same catalog can be opened from Slack. Apps and groups sync from Okta, Entra, and Google Workspace, and each role maps to an identity provider group. So the request starts with better context instead of an email or a vague Slack message.

Then Multiplier’s Approval Workflows route the request to the right person, whether that’s a manager, app owner, or a specific user. Approvers can act in Jira or Slack, and the decision stays tied to the Jira issue. That matters more than it sounds. It cuts the dead time between “approved somewhere” and “recorded nowhere,” which is a big part of the impact of delays.
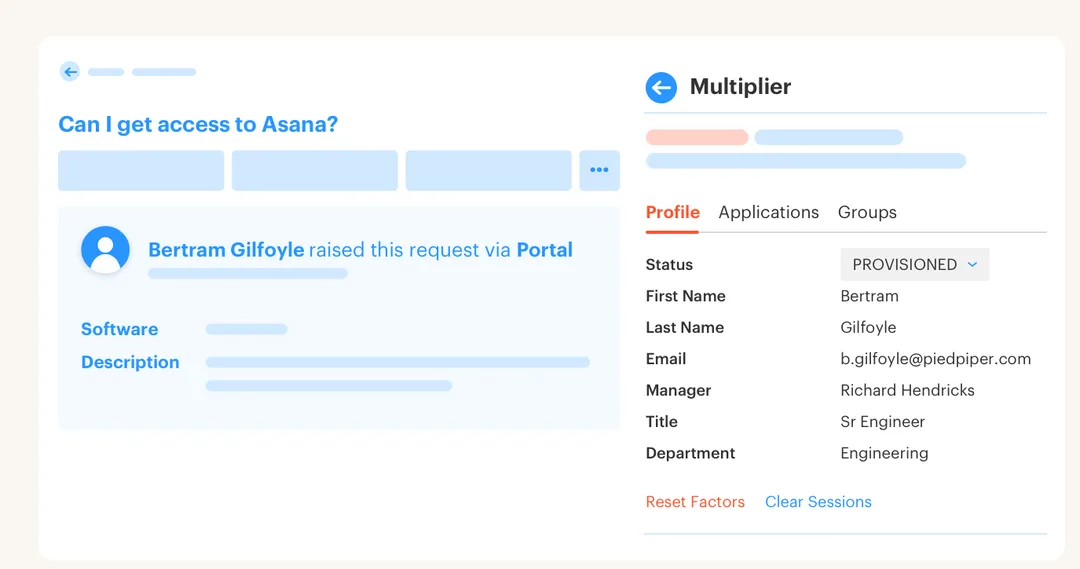
For teams trying to cut context switching and stop chasing approvals manually, this is usually where the first big win shows up. If you want to look at that flow in your own environment, Learn More About Multiplier.
Faster provisioning, temporary access, and cleaner evidence
Once a request is approved, Multiplier can provision through identity provider group mappings. That means the approved Jira issue can trigger the add or remove action in Okta, Entra, or Google Workspace, with the outcome written back to the ticket. Multiplier provisions through identity provider groups, not directly inside each SaaS app, and that boundary matters. But for teams already using group-based access, it removes a lot of manual follow-up.

Multiplier also supports Time-Based Access, so users can request a duration like 1, 6, or 24 hours and have access revoked automatically when the timer expires. That’s a practical fix for the impact of delays and the risk of standing privilege. Instead of granting broad access to avoid another ticket later, you can grant the narrow access needed right now and know it will be removed.
For certification work, Multiplier’s Access Reviews run in JSM and show reviewers user details, group memberships, last login, and recommendations. Reviewers can keep or revoke, and revocations can remove users from the relevant identity provider groups while documenting the change in Jira. If SaaS waste is part of your problem, Auto Reclaim can identify inactive users from identity provider login data, send warnings, and revoke access after the grace period. That’s especially useful if delays have pushed your team toward overprovisioning just to keep work moving.
Before you go back to another quarter of spreadsheets, screenshots, and cleanup, Get Started With Multiplier.
A slower access process creates bigger problems than most teams expect
The impact of delays is never just the delay. It spills into security, cost, employee experience, and audit work.
If your access model still depends on Jira in one place, approvals in another, manual group changes in a third, and spreadsheet evidence at the end, you don’t really have a governance system. You have people holding a fragile process together. The better move is to put governance where the work already happens, inside Jira and Slack, and let the identity provider execute the change cleanly.
Frequently Asked Questions
How do I set up time-based access for users?
To set up time-based access with Multiplier, you can follow these steps: 1) When users submit a request through the Application Catalog, they can select a duration for access (like 1, 6, or 24 hours). 2) After the request is approved, Multiplier automatically provisions access and sets a timer to revoke it once the duration expires. 3) Ensure that your applications are configured to allow time-based access. This setup helps minimize standing privileges and ensures users only have access when they truly need it.
What if my team is overwhelmed with access requests?
If your team is struggling with a high volume of access requests, consider using Multiplier's Application Catalog. This feature allows employees to easily browse and request access to approved applications directly within Jira or Slack. By streamlining the intake process, you can reduce the administrative burden on your IT team. Additionally, setting up automated provisioning can help speed up the process, ensuring users get access quickly without manual intervention.
Can I automate access reviews with Multiplier?
Yes, you can automate access reviews using Multiplier's Access Review feature. Start by creating a review campaign within Jira Service Management. 1) Select the applications you want to include, ensuring they are marked as 'Approved.' 2) Assign reviewers who will evaluate user access based on real-time data like last login and group memberships. 3) Once the review is complete, Multiplier automatically handles any revocations and documents changes in Jira, making the process efficient and auditable.
How do I ensure approvals are not missed?
To avoid missed approvals, use Multiplier's Approval Workflows. This feature routes requests to the appropriate approvers directly within Jira or Slack. 1) Configure the workflow to automatically notify approvers via email and Slack DMs, providing them with one-click options to approve or deny requests. 2) Ensure that all approvals are logged back to the Jira ticket, maintaining a clear record of decisions. This integration helps keep the process organized and reduces the chances of approvals getting lost in email threads.