
![Centralized Workflows for Faster Access Management [2026]](https://cdn.prod.website-files.com/60cc3b1de50f53117a9c8119/6a0f9eb8ffdd16d3206ab77a_centralized-workflows-for-faster-identity-provisioning-hero-1779408525848.jpeg)
75% of access requests can be fully automated if the workflow is built around the place where work already happens. For most IT teams, centralized workflows for faster access aren't really about buying another governance tool. They're about stopping the split between Jira, Slack, your identity provider, and whatever spreadsheet someone still updates the night before an audit.
I've seen this pattern a bunch. The team thinks the problem is approvals. Or provisioning. Or users asking in the wrong Slack channel. The bigger issue is that access work is scattered across four systems, so nobody can move fast without creating risk.
Key Takeaways:
- Centralized workflows for faster access work when intake, approval, provisioning, and evidence live in one system.
- Policy-heavy least privilege fails if IT still has to chase people and remove access manually.
- A self-service app catalog should start with the top 20 requested apps, not the full SaaS estate.
- Time-bound access is the practical way to reduce standing privilege without blocking employees.
- Access reviews should produce evidence as work happens, not force teams to rebuild proof every quarter.
Why Faster Access Breaks When Workflows Split
Faster access breaks when the request, approval, provisioning, and audit trail live in different places. The team may have Jira tickets, Slack approvals, Okta or Entra groups, and spreadsheets that all tell part of the story. Nobody owns the full chain, so speed and control start fighting each other.

The Split Between ITSM and Identity Is the Real Bottleneck
A product manager pings #it-help in Slack at 9:13 AM Tuesday asking for Figma Editor access before a 10 AM design review. Someone replies, "Can you file a Jira ticket?" The ticket gets created with half the details. The approver misses the notification because it's buried in 40 other Jira emails. IT finally adds the user to the right group in Okta at 11:47 AM. Someone leaves a comment that says "done" for audit evidence. The design review already happened without her.
The funny part is that every system did its job. Jira captured the request. Slack carried the conversation. The identity provider made the change. The spreadsheet maybe caught up later. The workflow failed because the systems didn't share enough context to make the next action obvious.
I've seen teams try to fix this with stricter policy. More required fields. More approval rules. More quarterly reviews. That's a reasonable read of the problem — policy matters. If the work still jumps between tools, stricter policy just creates a more formal mess.
If you're already running access work through Jira and Slack, the fastest path is usually not adding another portal. It's getting the existing workflow to carry the request, decision, change, and evidence from start to finish. If you want to see the Jira-native version of that path, Learn more about Multiplier.
Why Policy-Heavy Least Privilege Usually Loses
Least privilege sounds clean on a slide. In real life, it gets messy fast because employees need access right now, managers are busy, and IT doesn't want to become the department of "no." Broad access becomes the workaround. Not because security wants it. Because operations can't keep up.
The better question is simple: can the team grant access quickly and remove it automatically when the need is gone? If the answer is no, least privilege becomes a quarterly cleanup exercise. If the answer is yes, least privilege becomes part of the daily workflow.
NIST's access control guidance talks about account management, authorization, and revocation as ongoing controls, not once-a-quarter theater. The practical version of that is boring in a good way. Every grant has an owner. Every approval is tied to a request. Every elevated permission has an expiry.
The hidden cost isn't just slow access. It's the standing privilege that builds up because removing access takes more effort than granting it.
The Audit Trail Shouldn't Be Rebuilt Later
Audits get painful when evidence is treated like a separate project. Someone exports users from the identity provider, matches rows to Jira tickets, hunts through Slack threads, and screenshots approvals because the original workflow didn't preserve the proof. I've been in those rooms. Nobody is having fun.
A mid-market SaaS team can handle that once. Maybe twice. At 500 employees, it becomes a recurring tax. At 1,000 employees, the tax starts shaping how IT operates because every access decision might need to be explained later.
The overlooked move is to make the ticket the evidence container. The request, approval, provisioning result, revocation, and review decision should all land on the same record. Not because auditors love Jira. Because the work already started there.
Access governance is like a warehouse receiving dock. If every box gets scanned at the dock, inventory is easy. If half the boxes come through side doors, you spend every Friday walking around with a clipboard trying to figure out what arrived, what left, and who signed for it.
How to Build Centralized Workflows for Faster Access
Centralized workflows for faster access should start with the highest-volume access paths, then add automation where the decision rules are already clear. The mistake is trying to govern every app on day one. Start with the requests IT sees every week, then expand as ownership and group mappings become cleaner.
Diagnose the Requests That Are Already Repeatable
Pull the last 30 days of access tickets and sort them by app, role, approver, and provisioning action. If the same app appears 10 or more times, or if the same role gets granted the same way every week, that workflow is ready to centralize. Don't start with edge cases. Start where repetition is obvious.
The first pass is a simple diagnostic. How many requests arrive outside Jira? How many need IT to ask follow-up questions? How many approvals happen in Slack but never make it back to the ticket? How many grants require the same group assignment in Okta, Entra, or Google Workspace?
I've seen teams get surprised by this audit. They think they have 40 different access problems. Then they find 8 recurring patterns creating 70% of the volume. Pretty normal.
Use these thresholds:
- If more than 20% of requests arrive outside the service desk, centralize intake first.
- If more than 30% need follow-up questions, fix the request form before automating provisioning.
- If one app gets 10 or more requests per month, add it to the catalog.
- If approval takes more than 24 hours for low-risk apps, define auto-approval rules or default approvers.
- If elevated access stays active past 7 days, make that app time-bound.
A team like Videoamp hit the classic version of this. As they grew from 100 to 500 employees, Tuesdays started filling up with access requests after Monday onboarding. The breaking point wasn't that users were unreasonable. The request path didn't collect enough information, and app ownership wasn't clear enough to move quickly.
Build the App Catalog Around Decisions, Not Apps
A useful app catalog isn't a pretty list of software. It's a decision system. Each tile should answer three questions before IT touches anything: what app is being requested, what role is needed, and who has authority to approve it. Without those answers, the catalog becomes a nicer front door for the same manual work.
I like starting with 20 sanctioned apps. Not 200. The top requested tools, the ones with clear owners, and the ones where roles map cleanly to identity provider groups. Viewer, Editor, Admin. Simple stuff first.
The counterargument is fair. If you're going to build a catalog, why not make it complete? Completeness slows implementation, and a half-built catalog with the right 20 apps beats a giant catalog nobody trusts. The first goal is volume reduction, not perfect coverage.
A good app catalog entry should have:
- Approved app status: only sanctioned apps appear to employees.
- Clear role options: each role maps to a real access level.
- Named approver: manager, app owner, or specific user.
- Identity group mapping: each approved role points to the right group.
- Fallback path: non-SSO apps still create a ticket and audit record.
Atlassian has pushed Jira Service Management as a system for service delivery because the ticket is where request context, ownership, and status already live. For access workflows, that matters. The closer the catalog is to the service desk, the less training you need to get adoption.
Route Approvals Where People Actually Respond
Where do your managers actually live during a workday? Email works for some teams. Jira queues work for others. Slack works because it's where managers already spend six hours a day. The point isn't that chat is magic. Approvals need to happen where delay is least likely.
Set a simple rule. If the request is low-risk and the role is common, route it to a default approver or auto-approve it after intake validation. If the request is high-risk, route it to the app owner. If the request involves sensitive data or admin access, require a named security or system owner.
The danger is over-routing. Three approval layers might feel safer, but each extra handoff adds delay and creates more places for evidence to break. In my view, two approvals should be the ceiling for normal app access. More than that usually means the app needs a better risk model.
A practical approval map looks like this:
- Low-risk role, common app: manager or auto-approval.
- Business app with cost impact: app owner approval.
- Admin role or sensitive system: app owner plus security owner.
- Temporary elevated access: app owner approval with a required expiry.
- Break-glass access: time-bound grant with after-action review.
Synthesia is a good proof point here. During 4x headcount growth, they were tracking requests through Slack channels and Notion boards. After moving access requests into a governed Jira and Okta workflow, they processed 3,800+ access requests in a year, with 75% fully automated. A 4-person IT Ops team supporting 420+ employees is only possible when approvals don't live in five places.
Make Provisioning Follow the Approval Automatically
Provisioning should be the mechanical part of the workflow. Once the right person approves the right request, IT shouldn't have to copy the user into the identity provider, search for the right group, add the membership, and then go back to Jira to type "done." That is where mistakes creep in.
The mechanism is pretty straightforward. Map each catalog role to one or more identity provider groups. When the ticket reaches the approved status, the workflow adds the user to the mapped group through Okta, Entra, or Google Workspace. The ticket records the action, including whether it worked or failed.
If a request can't be provisioned through group membership, don't fake automation. Keep the ticket path, capture approval, and mark the app as manually provisioned. That still improves audit quality because the decision and evidence are centralized, even if the final grant happens elsewhere.
The 80% rule works well. If 80% of a workflow can be automated safely, automate that part and leave the remaining 20% explicit. Trying to automate 100% too early usually creates weird exceptions and broken trust. Nobody wants that.
After approval, the workflow should write back:
- Who approved it: the person or role that made the decision.
- What changed: group added, license assigned, or manual task created.
- When it happened: timestamp tied to the ticket.
- Whether it worked: success or error status.
- What happens next: closure, expiry, or review requirement.
That last line matters more than people think. Fast access isn't enough. Fast access with a clear end state is where governance gets better.
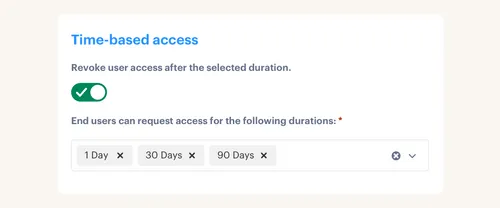
Use Time Limits for Roles That Create Real Risk
Time-bound access is the easiest way to stop standing privilege from piling up. If someone needs admin access for 1 hour, 6 hours, or 24 hours, the workflow should grant it for that window and remove it when the timer expires. No calendar reminder. No "I'll clean it up later."
The decision rule is clean. If the role gives production access, admin permissions, sensitive data access, or financial system access, make it temporary by default. If the role is a normal seat in a day-to-day tool, use standard approval and review cycles instead. Not everything needs just-in-time access.
Some teams push back here, and I get it. Temporary access can feel annoying when engineers are in the middle of an incident at 2 AM. The better design is to allow extensions when a prior request was already approved, while still preserving the expiry logic. You reduce friction without turning temporary access into permanent access by accident.
Stavvy is a useful example. They had long-lived privileged access and needed a practical way to minimize human access as they scaled. With time limits and Jira-native requests, they cut privileged access by 85%. The lesson isn't that every company needs the same number. The lesson is that privilege drops when expiry is built into the request, not left to memory.
A good threshold:
- 1 hour for emergency or break-glass access.
- 6 hours for maintenance work.
- 24 hours for short project tasks.
- 7 days only when the business owner can explain why.
- Anything longer should move into a formal role or access review.
Treat Access Reviews as Enforcement, Not Reporting
Access reviews fail when they become a spreadsheet ritual. Managers rubber-stamp rows because they don't have context. IT chases completion. Security accepts weak evidence because the deadline is coming. Everyone knows the review happened, but nobody is 100% sure it reduced risk.
A better review starts with usage context. Show the reviewer the app, user, group, department, job title, and last login. Then ask for a decision: keep or revoke. If the reviewer chooses revoke, the workflow should remove the group membership and create the evidence automatically.
The threshold I like is 90 days of inactivity for review recommendations, with shorter windows for expensive or sensitive apps. Finance may care about reclaiming licenses after 30 days. Security may care about admin roles after 7 days. Different risk, different timer.
Access reviews should answer three questions:
- Should the user still have access?
- Who made that decision?
- Was the decision enforced?
The third one is the part most teams miss. Reporting that someone should lose access is not the same thing as removing it. Centralized workflows for faster cleanup only work if revocation is automatic, not advisory.
How Multiplier Anchors Access Governance in Jira
Multiplier anchors access governance in Jira by connecting the catalog, approval, provisioning, expiry, and review record to the Jira issue. The work still runs through JSM and Slack, but the identity changes happen through Okta, Entra, or Google Workspace. Audit evidence gets created while the workflow runs.
Catalog, Slack Approvals, and IDP Provisioning Stay Connected
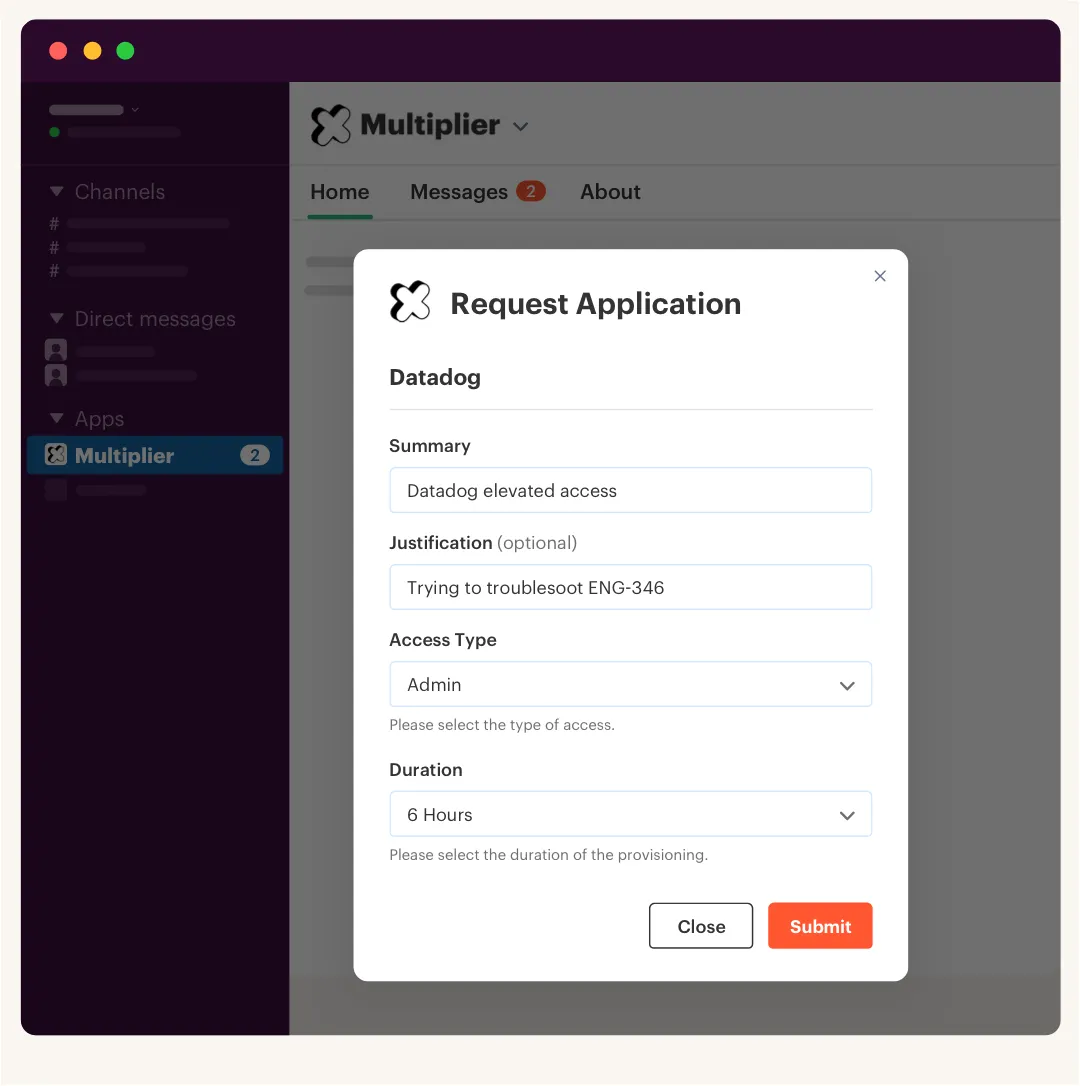
Multiplier's Application Catalog lets employees request approved apps from the JSM portal or Slack, with role choices mapped to identity provider groups. Once the request is approved, provisioning happens through those mapped groups, and the Jira issue records the change. For teams drowning in follow-up questions, that changes the operating rhythm fast.

The important part is that Slack doesn't become another side channel. Approvers can act in chat, but the Jira issue remains the system of record. That matters when you're trying to prove who approved what, when it happened, and what access was granted.
The clean version looks like:
- Employee request: app and role selected from the catalog.
- Approval routing: manager, app owner, or named approver gets the request.
- Provisioning: identity provider group membership changes after approval.
- Evidence: the Jira issue captures the request, approval, and provisioning result.
- Closure: the ticket can move forward without manual copy and paste.
That is how centralized workflows for faster access stop being theory. The workflow carries the context.
Time-Bound Access and Reviews Keep Cleanup From Becoming a Project
Multiplier supports time-based access where requesters choose a duration like 1, 6, or 24 hours, and expiry removes the user from the mapped identity provider group. Access Reviews run inside JSM with reviewer decisions, usage context, revocations, and CSV or Vanta-ready evidence. Those two features attack the same problem from different angles.
Time-bound access handles the day-to-day risk of elevated permissions. Access reviews handle the campaign-level question of who still needs what. Together, they reduce the amount of cleanup that has to happen after the fact.
For a team trying to stand up better governance without forcing employees into a separate IGA portal, the path is pretty practical. Start with the app catalog. Add Slack approvals. Map the cleanest roles to identity provider groups. Then apply time limits and access reviews where risk or audit pressure is highest.
Ready to make access requests faster without losing the audit trail? Get started with Multiplier.
Why Faster Access Starts With Better Operating Discipline
Centralized workflows for faster access aren't really about speed. They're about operating discipline. When request intake, approvals, provisioning, expiry, and evidence all live in the same workflow, IT doesn't have to choose between moving fast and staying clean.
The old way made teams rebuild governance after the work happened. The better way makes governance part of the work itself. Once that shift happens, access stops feeling like a queue to manage and starts feeling like a system you can trust.
Frequently Asked Questions
How do I set up time-bound access with Multiplier?
When submitting a request through the JSM portal or Slack, select a duration — 1, 6, or 24 hours. Once approved, Multiplier provisions the access and sets a timer. When it expires, the group membership is removed automatically. No calendar reminder, no manual cleanup. Just make sure the app is configured for time-based access in your catalog settings first.
What if I need to request an app not listed in the catalog?
Use the 'Other' option in the JSM portal or Slack. Provide the app name and any context IT needs, then submit. It creates a Jira ticket for review and keeps the approval process documented — even for apps that aren't SSO-connected. The audit trail stays intact regardless.
Can I automate approvals for low-risk access requests?
Yes. In your workflow settings, define default approvers for common apps and set auto-approval rules based on role or risk level. Low-risk, common roles can approve on intake validation alone. Approvers still get notified through JSM or Slack if manual review is needed. The goal is removing friction from the routine stuff so IT can focus on the edge cases that actually need attention.
When should I conduct access reviews?
Every 90 days is a reasonable default, but it depends on the app. Finance and admin roles might need 30-day windows. Sensitive systems might warrant monthly reviews. In Multiplier, create a campaign in Jira, pick the apps, assign reviewers, and set a date range. Reviewers see last-login data and role context, so decisions are based on actual usage — not gut feel. Revocations happen automatically when reviewers choose to remove access.
Why does Multiplier integrate with identity providers?
Because manual provisioning is where mistakes happen. Multiplier maps approved roles directly to identity provider groups, so when a request is approved in Jira, the user gets added to the right Okta or Google Workspace group without IT having to touch it. The ticket records the change automatically — who approved it, what changed, and when. And when access expires or gets revoked, the group membership is removed the same way. The audit trail builds itself.







