

72% of access issues still trace back to process gaps, not some exotic policy failure. And if the challenges of manual access landed on your desk this week, you already know the pattern: somebody needed access fast, approval floated around Slack, and no one was fully sure when that access was supposed to come back off.
Most teams treat manual access like an annoying admin chore. I think that’s the mistake. It works just well enough to survive for a while, then headcount climbs, an auditor shows up, or one ugly incident reveals you never really had least privilege at all.
Key Takeaways:
- The biggest challenges of manual access aren’t just delay. They’re standing privilege, weak evidence, and inconsistent revocation.
- A simple rule works: if elevated access lasts more than 24 hours, it should expire by default.
- The real bottleneck usually isn’t policy. It’s the split between Jira, Slack, your identity provider, and spreadsheets.
- Good access governance starts with one operating model: request, approve, provision, review, revoke, all tied to one record.
- Access reviews get dramatically better when reviewers can see usage context like last login, not just a spreadsheet row.
- Time-bound access beats policy-heavy governance when your team is lean and moving fast.
- If you want a cleaner path, Learn more about Multiplier.
Why Manual Access Breaks Faster Than Most Teams Realize
Manual access usually doesn’t fail all at once. It frays at the seams. Jira has the request, Slack has the nudge, Okta or Entra has the real permission, and audit proof winds up in a spreadsheet, a screenshot folder, or somebody’s memory. That messy split is what turns the challenges of manual access from “a bit annoying” into “why are we explaining this to an auditor at 4:47 PM?”

The hidden tax is in the handoffs
Three systems is usually the breaking point. That’s the Handoff Tax, and it’s the simplest way I know to diagnose the challenges of manual access before they become a formal incident. Count how many systems a request has to cross before the user gets access and before the evidence is complete. If that number is above 3, your process is fragile already.
Picture a workplace tech lead at 8:14 AM on Tuesday. They open Jira and see 18 pending access requests sitting in the queue. Seven approvals are stuck in Slack. Four managers replied in email because that happened to be open on their phone. By noon, two new hires still can’t do their jobs, one admin role got granted without an expiry, and the tech lead is quietly doing math on how bad this will look during SOC 2 evidence collection.
It feels like ops work. It’s actually systems debt. Like a relay race where every baton pass happens on a different track, the loss isn’t in the sprint. It’s in the handoff. And once you see that, the next problem gets easier to spot.
Manual access creates standing privilege by accident
A fintech company can have a clean policy doc and still have ugly privilege sprawl. That’s the part people underestimate. Standing privilege usually doesn’t appear because a team is reckless; it appears because revocation is manual, and manual cleanup is the first thing to slip when the week gets chaotic.
If an engineer gets elevated production access for one incident and nobody removes it after the incident, the exception hardens into the baseline. That’s why my rule is blunt: if access is privileged and temporary in intent, it should be time-bound in execution. If you can’t auto-revoke it, assume it will linger. Not elegant. Very useful.
And yes, there’s a fair counterpoint here. Standing access can feel operationally easier for on-call teams and incident responders. True. But ease at request time creates risk at clean-up time, and the challenges of manual access are mostly clean-up problems wearing a provisioning costume.
One fintech team in the source material had privileged access piling up after growth and acquisitions. Once they switched to a just-in-time model, they reduced privileged access by 85% and automatically revoked more than 1,300 requests after approved windows ended. That’s the difference between writing least privilege and enforcing it.
Audits get messy because evidence is an afterthought
What happens three months later is where manual access really embarrasses you. The access got granted. The employee was happy. Then an auditor asks who approved it, when it was provisioned, whether it was removed on time, and suddenly four people are reconstructing history from Slack screenshots and exported CSVs.
Spreadsheets do have a real advantage early on. They’re flexible, fast, and everybody knows how to use them. Fair enough. But once you have recurring reviews, multiple approvers, and role-based access, flexibility mutates into ambiguity. And ambiguity, in audit work, is just delayed pain with better formatting.
That’s why the challenges of manual access compound over time: evidence gets rebuilt after the fact, when the original trail is already cold. So if the problem is really the operating model, not the individual request, what should replace it?
The Real Problem Isn’t Requests, It’s the Operating Model Behind Them
The request isn’t the real issue. The machine behind it is. Most companies run access through a split system that was never built to enforce least privilege end to end, so the challenges of manual access keep showing up no matter how many policies you write.
The ITSM-IGA split is the bottleneck
Here’s the unpopular view: a separate governance portal often creates more theater than control. If the real work starts in Jira Service Management, forcing people into a second system just to complete the flow usually adds lag, not rigor.
The old model sounds disciplined. User files a ticket in JSM. Manager approves in Slack or email. IT checks a spreadsheet to map the role. Someone updates the identity provider manually. Someone grabs proof. Someone forgets expiry. The whole thing looks like governance from 30,000 feet and like improv theater from the ground.
Here’s the mechanism people miss: every extra operating surface creates one more place where the request state and the access state can drift apart. That drift is the engine behind the challenges of manual access. Policy-heavy governance without operational enforcement is just drift with nicer branding.
Reviews fail when reviewers lack usage context
What is a reviewer actually supposed to do with a spreadsheet that shows names, groups, and maybe an app label? Guess? That’s basically the current model in a lot of companies.
This is where the Usage Context Rule matters: if a reviewer cannot see job title, department, group membership, and last login, the review is low-signal by design. Before: reviewer gets a flat CSV and clicks Keep on 97% of rows because they have no basis to revoke. After: reviewer sees the employee changed departments 60 days ago, hasn’t logged into the tool in 94 days, and still holds a privileged group. Now there’s a real decision to make.
That’s one of the quietest challenges of manual access. Reviews look formal, but the decision quality is awful. NIST’s least privilege guidance is pretty clear on the principle here: permissions should align with current duties. Current duties require current context. Not stale exports stitched together by hand.
Lean teams need enforcement, not more process
Contrast a four-person IT team with a forty-person governance office. One can survive extra steps. The other can’t. A lean team supporting 400-plus employees does not need artisanal governance; it needs rules that remove work by default.
One AI company from the source material processed more than 3,800 access requests in a year and automated 75% of them. That matters because request volume changes the economics fast. At 20 requests a week, the challenges of manual access feel survivable. At 200, manual access stops being a workflow and becomes your hidden operating system.
There is an important exception. On very sensitive systems, you should not auto-approve everything. I agree with that fully. But deliberate approval is not the same thing as manual provisioning, manual expiry, and manual evidence collection. Keep the judgment. Kill the clerical work. Because once you separate those two, the better model comes into focus.
A Better Way to Enforce Least Privilege Without Slowing Work Down
The fix is not “more policy.” It’s a tighter operating model. Keep the human decision where it matters, automate the parts humans are bad at, and design the whole thing so the challenges of manual access don’t keep resurfacing under a different name.
Start with the 4D diagnostic
Four signals tell you whether manual access is merely annoying or actively expensive: Delay, Drift, Dark Evidence, and Duplicate Work. That’s the 4D diagnostic. If you have two or more, the challenges of manual access are already costing more than the tooling budget you’re trying to protect.
Ask these four questions:
- How many access requests need human follow-up after approval?
- How many elevated roles have no clear expiry?
- Could you produce approval and revocation evidence for a random request in under 5 minutes?
- Do reviewers see last login before deciding Keep or Revoke?
Here’s the scoring rule. Zero or one red flag: you have a process worth optimizing. Two red flags: you have an execution problem. Three or four: you have an access-control integrity problem, and you should treat it like one. Short version? If you can’t answer the auditor’s question in under five minutes, your process doesn’t own the truth.
Make temporary access the default for elevated roles
An engineer requests admin rights “for now.” Six weeks later, they still have them. That single before-and-after story explains why time-bound access beats vague good intentions.
The cleanest rule is simple: for admin roles, production systems, finance tools, and sensitive data, duration should be part of the request itself. Use the 1-6-24 rule. If the work can be done inside 1 hour, 6 hours, or 24 hours, force the requester to choose one of those windows. If they need longer, require a written reason and a named owner.
Yes, this adds some friction. That criticism is fair. People who are used to broad standing access will feel the change immediately. But this is the kind of friction that removes bigger friction later: fewer clean-up tasks, fewer review disputes, fewer “why does this person still have admin?” moments. Same work outcome. Much better risk profile.
Run access reviews with a revocation threshold
90 days is a useful starting point for many lower-frequency applications. Not a law. A starting point. Without a threshold, review means “stare at rows and hope pattern recognition saves you.”
I’d use what I call the Revocation Threshold: if the reviewer sees no current business reason and no meaningful usage signal, the default moves toward revoke, not keep. If the app is sensitive, shorten the inactivity window. If the app is expensive and rarely used, reclaim sooner. If the tool is seasonal or role-specific, carve out that population and review it manually instead of pretending a generic rule fits.
There’s a surprising upside here. Access reviews are not just compliance work; they’re also spend control. The same context that helps you trim unnecessary access also helps you trim unused SaaS licenses. That’s a rare win-win. If you want to see how that kind of enforcement works in practice, See how Multiplier works.
Build one record from request to revoke
One record. That’s the goal. Not five partial records and a heroic person in the middle.
Request, approval, provisioning, expiry, review, revocation. Same chain. Same evidence trail. Before: manager approves in Slack, IT provisions in Okta, security reviews from a CSV, audit asks for proof in Jira, and everybody swears they did their part. After: every state change ties back to the originating request, and the record can survive turnover, audits, and busy weeks without needing a forensic reconstruction.
Think of it like source control for access. If the commits are scattered across four repos and two chat threads, no one trusts the history. Pull the lifecycle into one authoritative record and suddenly the challenges of manual access stop multiplying in the dark. Which brings up the obvious question: what does that look like inside the tools people already use?
How Multiplier Puts This Model Into Jira and Slack
This is where the model stops being theoretical. Multiplier puts access governance inside Jira Service Management and Slack, then executes the change through your identity provider, which is exactly how you reduce the challenges of manual access without forcing everyone into yet another portal.
Access requests and approvals stop living everywhere
Requests that arrive through one channel behave very differently from requests that arrive through three. Multiplier’s Application Catalog gives employees a Jira-native place to request approved apps and roles, either in JSM or through the Slack app. That cuts one of the biggest challenges of manual access right away: missing context because the request started in whatever channel was convenient that moment.
Then approvals route to the right person, whether that’s a manager, app owner, or named approver. Approvers can act in Jira or Slack, and the request stays anchored to the issue. No separate governance portal. No side quest. For a lot of companies, that’s the difference between a process people follow and one they quietly route around.
Provisioning, expiry, and reviews get enforced in the same flow
Approved should mean enforced, not “someone will get to it.” That’s the line that matters.

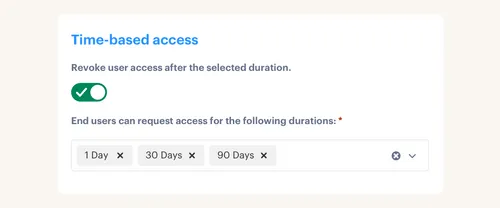
Multiplier’s automated provisioning works through identity provider groups. Once the request hits approved status, it can add or remove the user from mapped groups in Okta, Entra ID, or Google Workspace and write that action back to the Jira issue. For elevated roles, Time-Based Access lets requesters choose a duration like 1, 6, or 24 hours, after which access is removed automatically as long as the grant is managed through identity provider group membership.
That last part matters more than it sounds. If provisioning happens outside the identity provider, auto-removal gets shaky fast. On the review side, Multiplier’s Access Reviews run in JSM with campaign workflows and reviewer context like user attributes, groups, and last login. Reviewers can mark Keep or Revoke, revocations can execute automatically, and the evidence links back to Jira. That’s how you close the loop the challenges of manual access usually leave wide open.
Manual Access Always Looks Cheaper Until You Count the Cleanup
Manual access looks inexpensive because the cost is smeared across people, tools, and future cleanup. Then it shows up as standing privilege, delayed onboarding, weak certifications, missing audit evidence, and wasted SaaS spend. Same cost. Different line items.
My view is pretty simple. Least privilege works when expiry is automatic, provisioning is authoritative, and reviews happen with real usage context. If those three things aren’t true, the challenges of manual access are still running the show, even if the policy deck looks polished.
If your team already lives in Jira and Slack, that’s where governance should live too. Because the process you can prove is the process you actually have.
Frequently Asked Questions
How do I set up time-based access for my team?
To set up time-based access using Multiplier, follow these steps: 1) When a team member requests access, they can select a duration for their access (like 1, 6, or 24 hours). 2) Ensure that the access request is approved through the appropriate channels in Jira Service Management (JSM). 3) Once approved, Multiplier will automatically provision the access and set a timer to revoke it after the selected duration expires. This helps enforce least privilege by ensuring that elevated access is temporary by default.
What if I need to revoke access quickly?
If you need to revoke access quickly, you can use Multiplier's integrated access review feature. 1) Create an access review campaign in JSM, selecting the apps that are in scope. 2) Assign reviewers who will have visibility into user roles, last login dates, and other relevant context. 3) Reviewers can mark users for revocation directly in the JSM dashboard, and Multiplier will automatically execute the revocation, ensuring that the evidence trail is maintained in the same system.
Can I automate access requests for new hires?
Yes, you can automate access requests for new hires using Multiplier's Application Catalog. 1) New employees can browse the catalog in JSM or via the Slack app to request access to approved applications. 2) The requests will automatically create Jira tickets, streamlining the intake process. 3) Once approved, Multiplier will handle provisioning through your identity provider, ensuring that new hires get the access they need without manual intervention from IT.
When should I conduct access reviews?
It's typically best to conduct access reviews every 90 days, especially for applications with lower usage frequency. 1) Set up a recurring access review campaign in JSM to ensure regular checks. 2) Use Multiplier's recommendations during the review process to identify inactive users or those with excessive privileges. 3) This not only helps maintain compliance but also optimizes your SaaS spend by reclaiming licenses from inactive users.
Why does my team struggle with access request approvals?
Struggles with access request approvals often stem from fragmented processes. To improve this: 1) Use Multiplier to centralize access requests within JSM, reducing the number of channels involved. 2) Implement automated approval workflows that notify the right approvers directly in Jira or Slack. 3) This keeps the process streamlined and ensures that no approvals get lost in email threads, making it easier for your team to manage requests efficiently.







