

387 new hires in 8 months will expose every weak access process you have. And if you're implementing self-service access portals while approvals still live in Slack threads, Jira comments, email chains, and someone’s memory, you're not really fixing access. You're just making the front door look nicer.
I’ve seen this pattern a lot. The team launches a portal, everyone feels good for a minute, and then the same broken process shows up underneath. Someone still has to chase the manager. Someone still has to add the user to the right Okta group. Someone still has to remember to remove access later. So the portal gets blamed, when the real issue is that the work behind the portal never changed.
Key Takeaways:
- A self-service access portal only works if intake, approval, provisioning, expiry, and audit evidence are tied together.
- If access requests still require manual group changes after approval, the portal is mostly cosmetic.
- Identity provider groups should be the execution layer, because they make access changes authoritative and auditable.
- Time-bound access should be mandatory for elevated roles, production systems, and sensitive data.
- Approval design matters more than portal design once request volume passes 50 access tickets per week.
Why Self-Service Access Portals Fail After Launch
Self-service access portals fail when they improve request intake but leave approvals, provisioning, revocation, and audit evidence scattered across tools. The portal becomes a prettier form on top of the same manual process. At scale, that creates slow access, standing privileges, and audit cleanup work.

The Portal Is Usually Not the Real Bottleneck
A lot of IT teams start with the portal because it’s visible. Employees complain that they don’t know where to request access. Managers complain that requests lack context. Security complains that no one can prove who approved what. Fair.
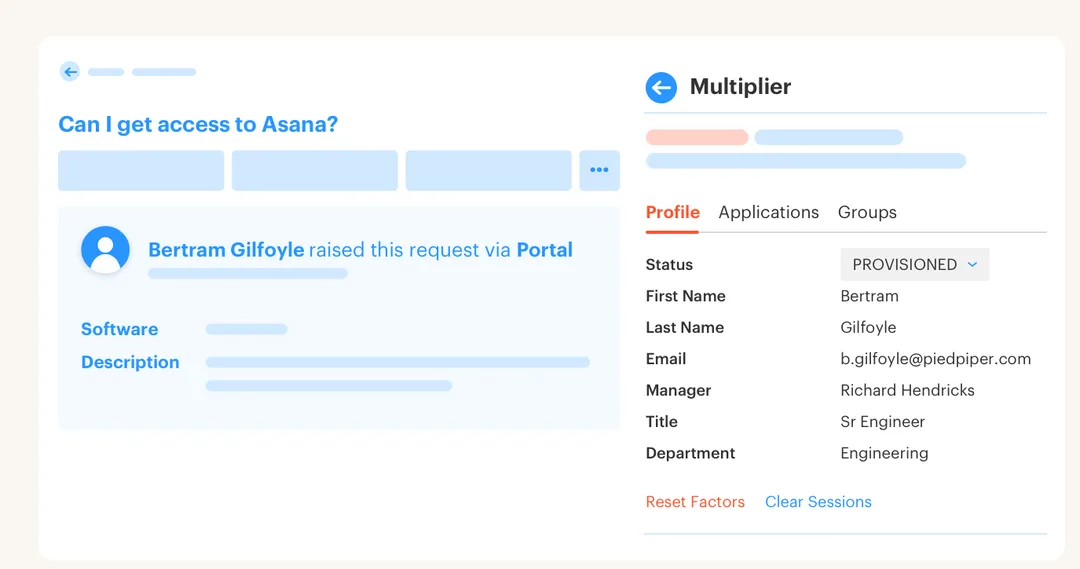
So the team builds a catalog. Apps are listed. Roles are named. Forms look clean. And for a week or two, everyone thinks the problem is solved.
Then Tuesday hits. A new cohort starts on Monday, and by Tuesday morning the IT queue is full of requests for Figma, GitHub, Salesforce, Jira projects, data tools, and some weird app only one department uses. The requester chose “Admin” because it sounded right. The manager missed the Slack message. The app owner is on PTO. The analyst still doesn’t have access by 3 PM, so someone grants a broad role just to get them moving. That’s how standing privilege grows. Quietly.
Videoamp had a version of this during growth from 100 to 500 employees. Tuesdays became the repeat problem because new hires submitted access requests with missing details, unclear ownership, and too much IT follow-up. After moving to a Jira-native app catalog, they processed 500+ requests in 6 months and saved 70+ hours of IT time. The lesson is pretty simple: the catalog worked because it was tied to the operating process, not because it looked nicer.
If you're trying to see what this looks like inside Jira rather than another access portal, Learn more about Multiplier.
Separate Governance Portals Create a Weird Split Brain
Separate identity governance portals make sense on paper. They give security a dedicated control layer. They give auditors a place to look. They give admins policy controls that feel very mature. I get the logic.

The problem is where people actually work.
Requests usually start in Jira or Slack. Approvals happen wherever the approver notices them. Provisioning happens in Okta, Entra ID, or Google Workspace. Evidence gets rebuilt later because the approval, the change, and the request don’t live together. It’s like running a restaurant where the order is taken in one system, cooked from a second system, paid for in a third system, and then someone recreates the receipt at closing time. You can make it work. But you’re asking for mistakes.
The better question isn’t “Do we have an access portal?” The better question is “Can a request move from intake to approval to identity provider change to audit record without someone doing copy and paste?” If the answer is no, implementing self-service access portals won’t remove the hidden work. It just changes where the work begins.
Access Risk Shows Up After the Ticket Closes
Access risk usually gets created after everyone thinks the request is done. The ticket closes. The employee gets access. The manager moves on. Nobody checks whether the access should expire.
That’s where security teams get stuck. NIST’s zero trust guidance pushes continuous evaluation and least privilege, but daily access operations often run on permanent group membership. Verizon’s 2024 Data Breach Investigations Report also keeps showing how credential misuse remains a major factor in breaches. Not every access request is risky. Long-lived access is where the risk compounds.
Honestly, access portals can make this worse if they make approvals faster without making revocation easier. You get more grants, faster. Then quarterly reviews become the cleanup crew for a process that should have enforced expiry up front.
The portal is the storefront. The identity provider is where the real access decision becomes real.
How to Implement Self-Service Access Portals That Actually Work
Implementing self-service access portals works when the portal is treated as one part of an access system, not the whole system. The better approach starts with request patterns, maps roles to identity provider groups, routes approval based on risk, and builds revocation into the original request.
Audit the Request Queue Before You Build the Catalog
Before you build anything, pull the last 60 to 90 days of access tickets and sort them by request type, app, role, approval path, and manual effort. You’ll learn more from that spreadsheet than from a portal design workshop. Sounds boring. It’s not.
The pattern usually jumps out fast. Maybe 15 apps create 80% of request volume. Maybe admin roles take 4x longer because no one knows the approver. Maybe GitHub requests are fast, but finance system requests need three follow-ups because the role names are unclear. Luno ran into this during rapid growth to almost 1,200 employees. Hundreds of routine requests came through Slack, email, and Jira, and IT had to chase approvals and manually assign Okta groups. After automating the pattern, they reduced access request workload by 80%.
The diagnostic is simple. Before approving a portal rollout, answer these questions:
- Which 20 apps generate the most access requests?
- Which roles are requested most often inside those apps?
- Which requests take more than 24 hours because approval ownership is unclear?
- Which requests require someone to manually update an identity provider group?
- Which access grants should expire by default?
If you can’t answer those, pause the build. Not forever. Just long enough to avoid turning messy access operations into a digital catalog of messy access operations.
Map Roles to Identity Provider Groups First
At 50 requests a week, manual provisioning starts looking manageable right up until someone gets sick, a new hire class starts, or a compliance deadline lands. The threshold I’d use is pretty direct: if a request type happens more than 10 times per month and the access is controlled by Okta, Entra ID, or Google Workspace, map it to a group before you put it in the catalog.
The group mapping matters because the identity provider should be the source of truth for access. Not the ticket. Not the Slack approval. Not the spreadsheet. The ticket should explain why access changed, who approved it, and when it happened. The identity provider should execute the change. That split is what makes the process clean.
A practical build sequence looks like this:
- Start with approved apps only, not every app in the company.
- Define 2 to 4 roles per app, like Viewer, Editor, Admin, or Finance Approver.
- Map each role to one or more identity provider groups.
- Test one low-risk app with auto-approval before adding sensitive apps.
- Require explicit approval for admin roles, finance tools, production access, and customer data.
Some teams resist this because group cleanup is annoying. Fair point. If your identity provider groups are a mess, portal work will expose it. But that’s useful. A self-service access portal is only as good as the permission model underneath it, and ugly groups are a sign the permission model has been ignored for too long.
Route Approvals by Risk, Not Politics
Who should approve access: the manager, the app owner, security, or IT? The answer should come from risk, not org chart politics. If you route every request to the manager, you’ll approve fast and miss app-specific risk. If you route every request to the app owner, you’ll create bottlenecks for routine access.
The better setup is conditional. Low-risk access can be auto-approved if the requester’s department and role match the policy. Standard access can go to the manager. Elevated access should go to the app owner or a named control owner. Production access, financial systems, and customer data should require tighter approval and a shorter duration. No drama. Just rules.
I’d use this approval model:
- Auto-approve: Low-risk apps where department and role clearly match the request.
- Manager approval: Standard business apps where the manager owns need-to-know.
- App owner approval: Systems where role choice changes risk.
- Security review: Privileged access, production systems, finance tools, and sensitive datasets.
- Time-bound approval: Anything elevated that should not stay granted forever.
The mistake is treating approval as a trust signal. It’s not. Approval is a routing decision. The real control comes from matching the approval path to the access risk and then enforcing the final decision through the identity provider.
If you want to compare that model against your current Jira and Slack flow, See how Multiplier works.
Make the Catalog Opinionated Enough to Prevent Bad Requests
The catalog is not the control if every app has an “Other” field and every role says “Full Access.” That’s just free-form access requests with nicer packaging. A good self-service access portal should narrow choices so employees can request the right thing without becoming permission experts.
Role names should be boring and obvious. Viewer. Editor. Admin. Billing Admin. Repository Maintainer. If a requester needs a meeting to understand the choices, the catalog is doing too much. If IT needs a follow-up question on more than 20% of requests, the form isn’t asking for the right context.
A good access catalog usually includes:
- Approved app list: Only sanctioned applications should appear by default.
- Plain role names: Roles should match how employees describe the work.
- Required business reason: One sentence is enough for low-risk access.
- Duration field: Required for elevated access, optional for standard access.
- Clear owner mapping: Every app needs a named owner, even if ownership is imperfect at first.
The hidden advantage is training. The catalog teaches employees what access is normal for their role. Over time, fewer people ask for broad access because the default path makes the narrow request easier. That’s where least privilege gets practical.
Build Expiry Into the Request, Not the Cleanup Project
Manual revocation and automatic expiry feel like small operational differences. They’re not. One depends on someone remembering later. The other makes the original request carry its own end date.
For elevated access, use a simple rule: if the user needs it for a task, incident, audit, deployment, or investigation, the access should expire. Start with 1 hour, 6 hours, 24 hours, and 7 days as standard options. Longer access can exist, but it should feel like an exception. Not the default.
A useful expiry policy looks like this:
- Production access defaults to 1 or 6 hours.
- Admin access defaults to 24 hours.
- Contractor access defaults to the contract end date.
- Temporary project access defaults to 7 or 30 days.
- Standard employee access gets reviewed quarterly or based on usage.
The best part is cultural. You stop having the same fight about whether least privilege slows people down. People get access quickly when they need it, and the system removes it when they don’t. No heroic cleanup. No awkward audit scramble. Just a cleaner loop.
Treat Audit Evidence as a Byproduct
Audit evidence shouldn’t be a separate job. If the request, approval, provisioning event, and revocation all live in the same ticket, the evidence is already there. If those actions live across five tools, someone has to rebuild the story later.
The decision rule I like is blunt: if an auditor asks why someone had access, you should be able to answer from one record. Who asked. Who approved. What group changed. When access started. When access ended. If you need screenshots from Slack, CSV exports from the identity provider, and a spreadsheet maintained by one tired admin, the process is broken.
A strong access record includes:
- Requester, app, role, and business reason.
- Approval path and approver decision.
- Identity provider group added or removed.
- Timestamp for provisioning and revocation.
- Duration or expiry rule.
- Review decision if access was certified later.
Some teams prefer dedicated IGA portals for audit depth, and for large enterprises with complex segregation of duties, that can be valid. The tradeoff is adoption. If the governance system sits outside the service desk, people work around it. For mid-market and high-growth teams running on Jira, the better bet is often to make the governed path the easiest path.
That’s really the whole game.
How Multiplier Runs Access Governance in Jira
Multiplier runs access governance inside Jira Service Management by connecting the request, approval, provisioning, expiry, and audit record to the same Jira issue. Employees request access in JSM or Slack, while approved changes execute through Okta, Entra ID, or Google Workspace groups.
Jira-Native Catalog With Identity Provider Execution
Multiplier’s Application Catalog gives employees a Jira-native place to request approved apps and roles, instead of sending access requests through Slack, email, and random tickets. Apps and groups sync from Okta, Entra ID, or Google Workspace, and only approved apps appear in the catalog. That keeps the portal focused.

Once a role maps to an identity provider group, Multiplier can provision through that group after approval. The important detail is that the access change happens through the identity provider, while the Jira issue keeps the record of the request and decision. That’s what removes the copy-paste step that caused Luno’s access queue to drag. A request that used to require 5 to 30 minutes of manual work can become a governed path with approval, group assignment, and ticket evidence tied together.
Slack Approvals and Time-Bound Access
Multiplier also supports approval workflows through JSM and Slack, so managers, app owners, or named approvers can make decisions where they already work. After approval, Multiplier transitions the Jira ticket and triggers the mapped identity provider action. No separate portal for approvers to remember. No side channel that disappears before audit season.
Time-Based Access is the bigger security win. Requesters can choose a duration like 1, 6, or 24 hours, and after approval, Multiplier adds the user to the mapped identity provider group. When the timer expires, it removes the group membership and records the change in Jira. That directly addresses the standing privilege problem from earlier: fast access when needed, automatic cleanup when the job is done. For teams implementing self-service access portals in Jira, Get started with Multiplier if you want the portal and the enforcement layer connected from the start.
What Changes When Access Work Lives in Jira
Self-service access portals work when they change the whole access motion, not just the intake form. The request should start in the system employees already use, route to the right approver, execute through the identity provider, expire when it should, and leave behind evidence without extra work.
That’s the shift. Not another portal. Not more screenshots. Not a quarterly cleanup project pretending to be governance.
If you're implementing self-service access portals, start with your highest-volume access requests, map the roles to identity provider groups, and make expiry part of the request. Once that loop works, everything else gets easier. Access gets faster. Least privilege becomes practical. And audit prep stops feeling like archaeology.
Frequently Asked Questions
How do I set up time-based access in Multiplier?
To set up time-based access in Multiplier, follow these steps: 1) When submitting an access request through the Jira Service Management (JSM) portal or Slack, select the duration for the access (like 1, 6, or 24 hours). 2) After the request is approved, Multiplier will automatically provision the access and set a timer to revoke it once the duration expires. 3) Ensure that the app's configuration allows for time-based access to enforce least privilege effectively. This approach helps minimize standing privileges and ensures access is only available when truly needed.
What if my access requests are still getting delayed?
If access requests are getting delayed, consider these steps: 1) Review your approval workflows in Multiplier to ensure they are set up correctly—route approvals based on risk rather than just the manager. 2) Use the Application Catalog to streamline requests, ensuring employees select from approved apps and roles. 3) Automate provisioning via identity provider groups to eliminate manual steps. This can significantly reduce bottlenecks and improve response times for access requests.
Can I customize the application catalog in Multiplier?
Yes, you can customize the Application Catalog in Multiplier. To do this: 1) Admins can add custom applications that are not single sign-on (SSO) enabled to capture approvals and maintain an audit trail. 2) Ensure that only approved applications are visible in the catalog to prevent confusion. 3) You can also tag apps for manual provisioning if needed, allowing for better management of access requests and ensuring that employees can easily find the apps they need.
When should I implement access reviews with Multiplier?
Implement access reviews with Multiplier when: 1) You have a growing number of users and applications, which makes manual reviews cumbersome. 2) You want to ensure compliance and security by regularly certifying user access. 3) You can automate the review process by creating campaigns in JSM, allowing reviewers to easily mark access as 'Keep' or 'Revoke' based on usage. This helps maintain a clean access environment and reduces the risk of overprovisioned access.
Why does my team need to map roles to identity provider groups?
Mapping roles to identity provider groups is crucial because: 1) It ensures that access requests are executed accurately and consistently through the identity provider, reducing manual errors. 2) It allows Multiplier to automate provisioning, which speeds up the access process. 3) This mapping creates a clear audit trail, linking requests, approvals, and changes, which is essential for compliance and security audits.



![How Often Should IT Review User Access? [2026 Guide]](https://cdn.prod.website-files.com/60cc3b1de50f53117a9c8119/6a66a1cf885673df12066292_how-often-should-it-teams-conduct-access-reviews-for-audit-trails-2-hero-1785110967342.jpeg)


