

Most IT leaders accept a heavy Tier-1 queue as normal. It is not. A big chunk of that backlog is optional work once you put a nocode automation playbook in place. The pattern is simple, but ignored. Measure where your queue bleeds time, remove the routine with no-code rules, and keep the risky bits behind approvals. The surprise is how fast it starts working.
I have seen 60 to 80 percent of manual tickets fade out within a quarter when teams commit to it. Not through heroics. Through a staged rollout, tight measurement, and guardrails that make operations feel safe. You get fewer interrupts, less context switching, and cleaner audits. Everyone wins.
Key Takeaways:
- Find the 20 percent of ticket types that create 80 percent of manual work
- Build a safe nocode automation playbook with approval gates and auto-revoke
- Use rollback tasks, rate limits, and change logs to avoid blast radius
- Prove reclaimed hours weekly, then scale what works
- Keep governance in Jira and Slack so the record and the change match
- Automate through your identity provider to make changes authoritative and auditable
Why Most Tier-1 Backlog Is Optional Work
Most Tier-1 backlog is optional because a large share of those tickets follow repeatable patterns with predictable outcomes. When you map the top request types and standardize inputs, you can remove manual handling without adding risk. The trick is starting with no-code rules and tight scoping, then expanding only after you see clean results.
The hard truth is not complexity. It is missing process. Without a shared intake form, a clear owner, and a simple rule, every “quick request” becomes bespoke work. That is why queues swell after headcount growth or a product launch. Intake gets noisy, approvals are scattered, and provisioning lives in side channels. Once you pull those back into one place with a small set of rules, the noise drops fast.
What Tickets Actually Belong In Tier-1
Tier-1 should handle high-volume, low-risk, well-defined tasks that do not need deep troubleshooting. Think password resets, app role changes for non-admin roles, mailing list joins, and access to common SaaS tools with preapproved roles. Those are the bread and butter of automation.
When those tickets arrive with the right context and route to the right approver, they do not need a human to click around in an admin console. The human step is often a safety blanket that adds delay without adding safety. You can replace it with a rule that checks a few facts, captures a clear decision, and executes a known change. That is where the hours hide.
Automation Candidates You Can Safely Remove
Start with simple, reversible entitlements and leave admin roles alone until later. If a change is group-based, can be removed cleanly, and has a clear owner, it belongs on your early list. The same is true for time-bound access where you can set an expiry and let the system clean up.
Once you test a few, your team will see the pattern. Tickets that once felt scary turn out to be lab work. You prove safety, expand scope, and watch the queue shrink. That is the flywheel you want.
- Non-admin SaaS roles that map to identity provider groups
- Access to standard Jira projects or Git repositories with read or write roles
- Email group or Google Group membership for functional lists
- Temporary access windows for production read-only views
The Root Cause: No Playbook, No Process
The real problem is not volume, it is lack of a shared playbook. Without a standard intake, a known approver, and a rule that governs the change, every request becomes custom work. That is where teams fail. They treat identical requests as unique because the system does not enforce sameness.
Work also lives in the wrong place. Tickets are in Jira, approvals happen in email or Slack, and provisioning happens in the identity provider. Evidence gets rebuilt in spreadsheets. You can run like that, but you will always lose time and miss revocations. Put the steps back together in one record, and the drag disappears.
Symptom vs Cause In IT Ops
Leaders complain about slow resolution times and rising queues. Those are symptoms. The cause is scattered processes that force humans to shuttle context between tools. Every hop adds friction. Every manual lookup adds delay. Every ad hoc exception becomes future debt.
When you see that clearly, the fix stops being mystical. You do not need more agents or a bigger queue. You need a way to standardize intake, encode decisions, and let the system execute changes where the source of truth lives. That is the playbook.
Where Work Really Happens Today
Most of the real work already lives in Jira and Slack. People open tickets, ask for approvals in chat, then someone flips a switch in Okta or Entra. The path is predictable, even if the mechanics are messy. That is why a Jira-native approach with chat approvals and identity-provider provisioning feels obvious once you try it.
Pull requests, approvals, and changes into one flow. Keep the audit trail on the ticket that started it. Make the identity provider the only place where entitlements change. You reduce risk and speed up access at the same time.
Automation Math: The Real Cost Of Manual Tickets
Manual handling burns time at each handoff, not just during the change. A single access request can touch the requester, the manager, the approver, and the admin. Each touch has wait time, context time, and click time. Stack that across hundreds of tickets, and the cost becomes obvious.
Data backs this up. Simple no-code rules in service desks reduce cycle time and error rates because they remove handoffs and standardize inputs. Atlassian’s guidance on Jira Service Management automation rules shows how teams use triggers and conditions to cut repetitive work safely. That is the baseline you want to build on.
Time, Money, And Risk On Every Manual Step
A manual approval step often adds a day of idle time. A manual group add takes two to five minutes if you already have the group open. Rework happens when the requester forgot to pick a role, or the approver is the wrong person. Each small miss adds friction that compounds through the week.
There is also risk. Humans forget to set expiries. Licenses stay assigned when projects end. Audit evidence gets rebuilt after the fact. Those misses cost real money and weaken least privilege. The queue hides this waste, which is why leaders underestimate it until the numbers are in front of them.
Backlog Growth Compounds Without Guardrails
Backlog growth is not linear. As requests pile up, people route around the system. They ping a friend for access or buy another license to avoid waiting. That creates shadow IT and overspend. Clean process with automation stops that drift, especially when evaluating nocode automation playbook.
Add guardrails like rate limits on auto-approvals and expiries on elevated roles. People get what they need fast, within a narrow window, and the system cleans up after. You cut risk while shrinking backlog. That is the win.
What It Feels Like To Live In The Queue for Nocode automation playbook
Living in a busy queue is messy. Your day gets sliced into five-minute chunks. You chase approvals. You click through admin panels and take screenshots for evidence. By Friday, you do not remember what you changed on Monday. It is exhausting.
I have been there. You think the answer is more hands. It rarely is. The answer is fewer touches on the same work. When the queue stops buzzing with the same four request types, the team gets real work done again. That is the shift you want.
The Human Tax On Your Team
Interrupts wreck deep work. Every “quick add to a group” drags an agent out of flow. Multiply that by dozens of times per day and you lose hours of focused time. Morale drops when the job feels like endless clicking. People burn out on toil.
Leaders pay a tax too. You spend time explaining to finance why license counts keep drifting or telling auditors why revocations were late. That is not strategy. That is cleanup. It is avoidable once you put a playbook in place.
Why Leaders Miss The Early Warning Signs
The queue hides repetition. Tickets look different on the surface, but many are the same change in disguise. Without tags or structured fields, you miss the pattern. By the time you see it, the team is already underwater.
A simple tagging pass exposes the truth. You will find a small set of request types driving most of the manual work. That is your gold mine. Fix those and the rest of the queue gets easier overnight.
The Nocode Automation Playbook You Can Run In 6 Weeks
A nocode automation playbook is a short, staged plan to remove routine work safely, measure reclaimed hours, and expand. Start with the few ticket types that drive most of the queue. Encode decisions into rules. Execute through your identity provider so changes are authoritative and auditable.
You are building a habit, not just a few rules. The habit is measure, automate, verify, and expand. Keep humans in the loop where risk is real, and let the system clean up with expiries and revocations. The playbook below is how you get there without drama.
Map The 20 Percent That Drives 80 Percent
Inventory your queue for four weeks. Tag every request with a normalized type and a role if it involves access. Pull a simple report that shows type, volume, average touch time, and wait time. Sort by hours consumed, not count.
You will see the same suspects: SaaS role adds, list memberships, common system access, light Jira or Git permissions. Those are your week one targets. Confirm the approver for each and write down the exact change you would normally make. Clarity here prevents mistakes later.
After you have the list, draft standard fields for each request so the intake is complete every time:
- Application name, role, and justification
- Requester manager and team
- Duration if time-bound is required
- Compliance tag if approvals differ by risk
Production-Safe Automation Patterns
Automations should be boring, visible, and reversible. Keep approvals in Jira or Slack for higher-risk roles. Provision through the identity provider so changes are anchored to source of truth. Set expiries for anything elevated. Write every change back to the ticket.
You can also use rate limits to avoid flood conditions. Cap auto-approvals per user or per group per day. Rollback tasks should live right next to the rule. If a change fails or behaves oddly, you know exactly how to unwind it. That is what builds trust with security and audit.
Give your rules a safety checklist before turning them on:
- Is the approver correct and visible on the ticket?
- Does the rule write success or error back to the record?
- Can the change be fully undone by removing a group or revoking a license?
- Is there an expiry or review for elevated roles?
The 6-Week Rollout And Measurement Plan
Run this as short sprints with a scoreboard. You are proving outcomes, not shipping a science project. Start narrow, measure weekly reclaimed hours, and expand only when the numbers hold, especially when evaluating nocode automation playbook.
Here is a simple plan you can copy:
- Week 1: Tag the queue, pick top three request types, draft fields and approvers
- Week 2: Ship intake changes, publish the rules, set expiries on elevated roles
- Week 3: Add Slack approvals for the higher-risk path, verify audit logs
- Week 4: Expand to two more request types, add rate limits, tune messages
- Week 5: Share reclaimed hours with leadership, capture agent feedback, fix rough edges
- Week 6: Roll out access reviews for one app to catch lingering standing access
Ready to cut Tier-1 volume without hiring more agents? See how Multiplier works.
How Multiplier Operationalizes The Playbook In Jira
Multiplier makes the nocode automation playbook real inside Jira and Slack by centralizing requests, approvals, and changes, then executing through your identity provider. The result is fast, auditable access with least privilege by default. You keep humans for judgment and let the system handle the rest.

Start with an app catalog in the JSM portal or Slack so intake is complete and consistent. Route approvals to managers or app owners inside JSM or chat. On approval, Multiplier adds users to mapped identity provider groups, sets timers for time-bound access, and writes every action to the ticket. That eliminates manual copy and paste and the screenshot circus.
Jira-Native Intake And Approvals In Slack
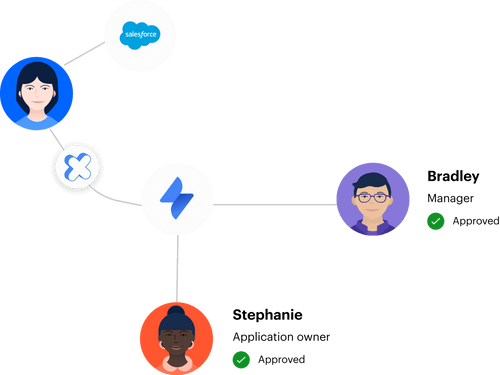
Employees browse a visual Application Catalog in the JSM portal or request access from Slack. Roles are mapped up front, which means the ticket carries the exact change you will make. Approvals land in JSM and as direct messages in Slack with one-click decisions. No one hunts through email threads.
When a request is approved, the ticket transitions and the system executes. The important part is where that execution happens. It happens through your identity provider, which keeps your source of truth aligned with the ticket. That is how you avoid drift and confusion.
Provisioning Through The Identity Provider
Automated Provisioning uses identity provider groups to grant or remove access. On approval, Multiplier calls Okta, Entra, or Google Workspace to add users to the right group, which pushes entitlements downstream. The ticket logs success or errors for visibility. This is the path to fewer errors and faster access.
If you want the technical receipts, group-based changes are a standard pattern in modern identity stacks. Okta documents their Groups API for membership changes. Operating at that layer is both faster and safer than ad hoc admin panel work.
Least Privilege And Audit Evidence By Default
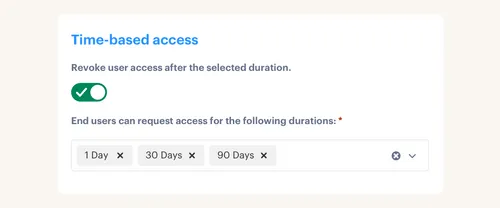
Time-Based Access shrinks exposure windows by making elevated access temporary. Requesters pick a duration, the system grants on approval, then removes access on expiry. Decisions, grants, and revocations all write to the Jira issue. Auditors get a clean timeline without side files.
Access Reviews run as Jira-native campaigns, so reviewers see usage context and can revoke directly. License waste drops with Auto Reclaim, which uses last-login data from your identity provider to pull back unused seats. Least privilege stops being a memo and becomes daily practice, which aligns with the spirit of CISA’s Zero Trust guidance.
Key capabilities that support the playbook:
- Application Catalog, a JSM app store experience that standardizes intake by app and role
- Approval Workflows in Jira and Slack, with clear owners and one-click decisions
- Automated Provisioning via identity provider groups, so access changes are authoritative
- Time-Based Access for just-in-time elevated roles that auto-expire on schedule
- Access Reviews and Auto Reclaim for ongoing cleanup and license savings
Want to see Slack approvals, time-bound access, and group-based provisioning working end to end? Learn more about Multiplier.
When you add it up, the earlier costs fade. The minutes per ticket to click through admin panels, the days of idle wait for approvals, and the audit rebuild at quarter’s end all disappear. A single source of truth, fewer touches, and automatic revocation remove the mess you saw in the Rational Drowning section. That is the transformation.
Before you wrap this up, consider the handoff risk you no longer accept. You will not miss expiries on elevated roles. You will not rebuild evidence in spreadsheets. You will not guess who owns an app this week. The system encodes the answers for you. Ready to turn the playbook on? Get started with Multiplier.
Conclusion
Most Tier-1 backlog is a process problem, not a people problem. Map the work, ship a nocode automation playbook with safety rails, and prove reclaimed hours every week. Keep requests, approvals, and changes in Jira and Slack, and execute through your identity provider so the record and the reality match.
Do that for six weeks and you will feel the change. Fewer interrupts. Faster access. Cleaner audits. The queue stops buzzing and your team gets its time back. That is the goal.
Frequently Asked Questions
How do I set up an Application Catalog in Multiplier?
To set up an Application Catalog in Multiplier, follow these steps: 1) Navigate to your Jira Service Management (JSM) portal and select the request type for access requests. 2) Use the Multiplier app to display approved applications as tiles with logos. Ensure each app has defined roles (like Viewer or Admin) mapped to identity provider groups. 3) Once set up, employees can browse the catalog to request access, streamlining the intake process and ensuring all requests include the necessary context.
What if I need to automate approvals for multiple applications?
If you want to automate approvals for multiple applications, you can use Multiplier's Approval Workflows. Start by mapping the workflow statuses in Jira to include 'Waiting for Approval' and 'Approved'. Designate default approvers for each application, or assign specific approvers based on the request type. This way, when an employee submits a request through the JSM portal or Slack, the right approver gets notified, and they can approve or deny the request with a single click.
Can I enforce time-based access using Multiplier?
Yes, you can enforce time-based access with Multiplier. When employees request access, they can choose a duration for their access (like 1, 6, or 24 hours). After approval, Multiplier provisions the access and automatically sets a timer to remove the user from the mapped group when the time expires. This approach helps minimize standing privileges and ensures that access is only granted when necessary.
How do I conduct access reviews with Multiplier?
To conduct access reviews using Multiplier, create an Access Review campaign in Jira. Start by selecting the applications you want to include (only those marked as 'Approved'). Assign reviewers for each app and set a start and end date for the campaign. Once launched, reviewers will receive notifications and can assess user access, marking users to 'Keep' or 'Revoke' based on their activity. Multiplier will automatically update group memberships based on these decisions, maintaining a clean audit trail.
When should I use Auto Reclaim for license management?
You should use Auto Reclaim when you want to optimize your SaaS spend by reclaiming unused licenses. Set inactivity thresholds (like 30 days) and grace periods for users to log in. If a user exceeds the inactivity threshold, Multiplier will notify them. If they remain inactive after the grace period, it will automatically revoke their access and generate a Jira ticket documenting the change. This helps ensure you're not paying for licenses that aren't being used.


![How Often Should IT Review User Access? [2026 Guide]](https://cdn.prod.website-files.com/60cc3b1de50f53117a9c8119/6a66a1cf885673df12066292_how-often-should-it-teams-conduct-access-reviews-for-audit-trails-2-hero-1785110967342.jpeg)




